Chapter 10 Visualising data with ggplot2
Learning goals
By the end of this chapter you should be able to:
- Build plots with
ggplot()and geoms. - Compare groups using histograms and box plots.
- Use facets to split plots into panels.
- Plot trends over time with lines and points.
- Decide when a bar plot is (and is not) appropriate.
Prerequisites
- You should be comfortable with importing data and using
filter(),select(),mutate(), andsummarise().
A tiny motivating example
Let’s start with a simple scatter plot. Run this and see what happens:
library(tidyverse)
mydata <- data.frame(
body_length_cm = c(4.2, 5.1, 5.6, 6.8, 7.4),
body_mass_g = c(9.5, 12.1, 14.0, 18.2, 21.5)
)
ggplot(mydata, aes(x = body_length_cm, y = body_mass_g)) +
geom_point()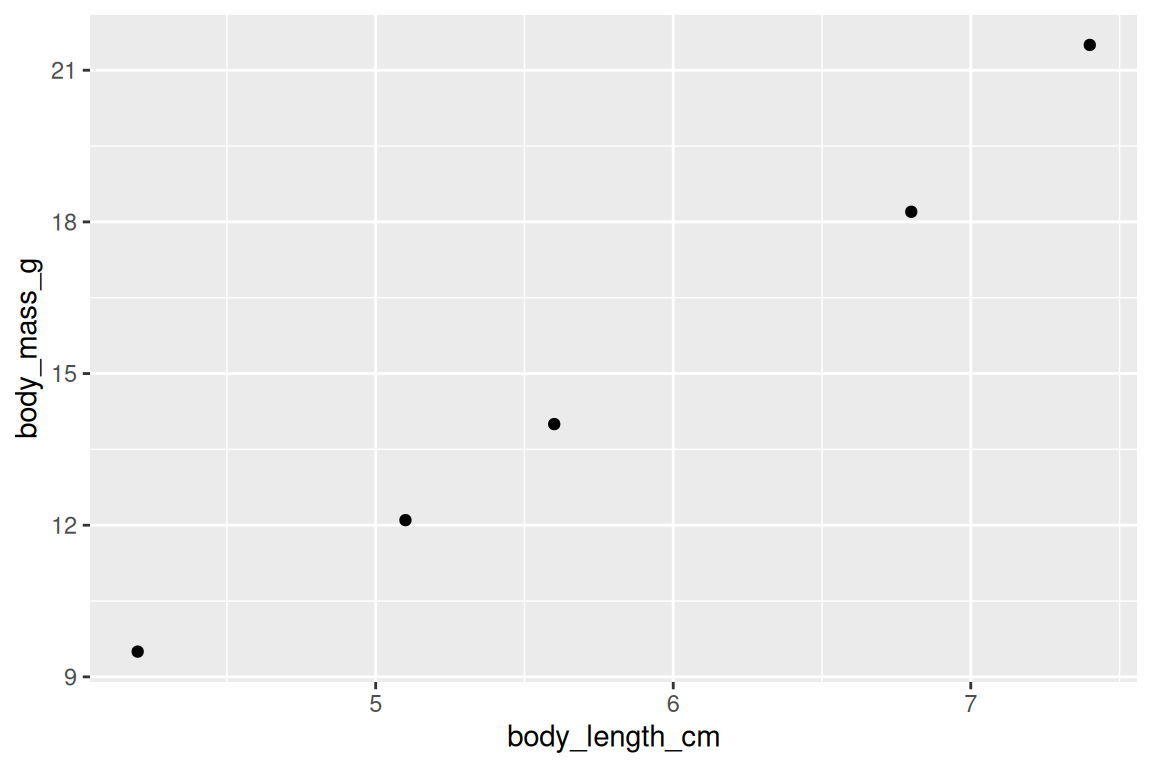
We have already made a plot: data + aesthetics + geom. That pattern will repeat throughout the chapter.
10.1 The data we will use
We will use the SDU clutch size data created at the end of the Data wrangling chapter. The file should be in CourseData/SDUClutchSize.csv.
Checkpoint: You should see columns like species, Year, and clutchSize.
10.2 Histograms
What we’re about to do: We will look at the distribution of clutch sizes. Histograms are the simplest way to see how values are spread.
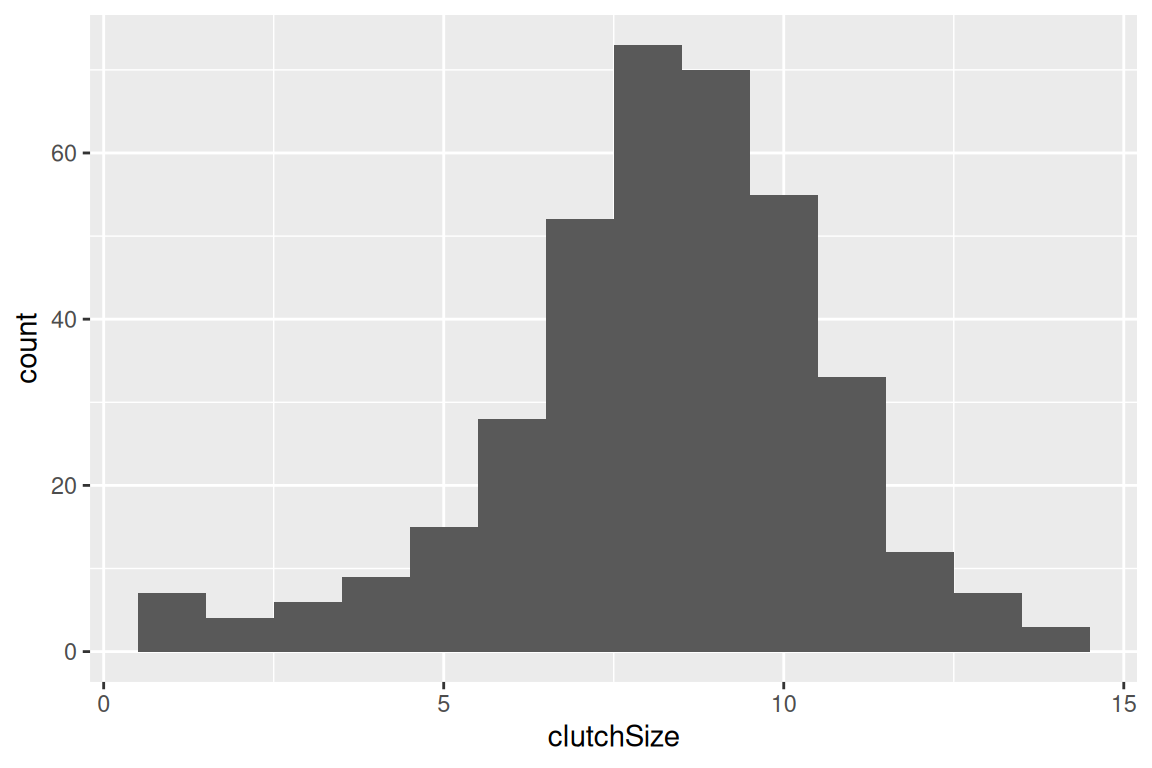
What just happened: Each bar shows how many nests have a particular clutch size (or range of sizes).
- What to look for:
- Where is the distribution centred?
- Is it roughly symmetric or skewed?
- Are there values that are rare or extreme?
Try this: Change binwidth to 0.5 or 2. What changes in the shape?
Common mistake: If your plot is blank, check that clutchSize exists with names(clutch).
Takeaway: Histograms show the shape of a distribution quickly.
10.3 Comparing groups in a histogram
What we’re about to do: We will compare clutch sizes between species.
clutch %>%
ggplot(aes(x = clutchSize, fill = species)) +
geom_histogram(binwidth = 1, position = "dodge")
What just happened: The bars are separated by species, so you can compare their shapes.
- What to look for:
- Do the peaks occur at different clutch sizes?
- Is one species more common (taller bars overall)?
Caution: Counts depend on sample size. If one species has more nests, it will look bigger even if the shape is similar.
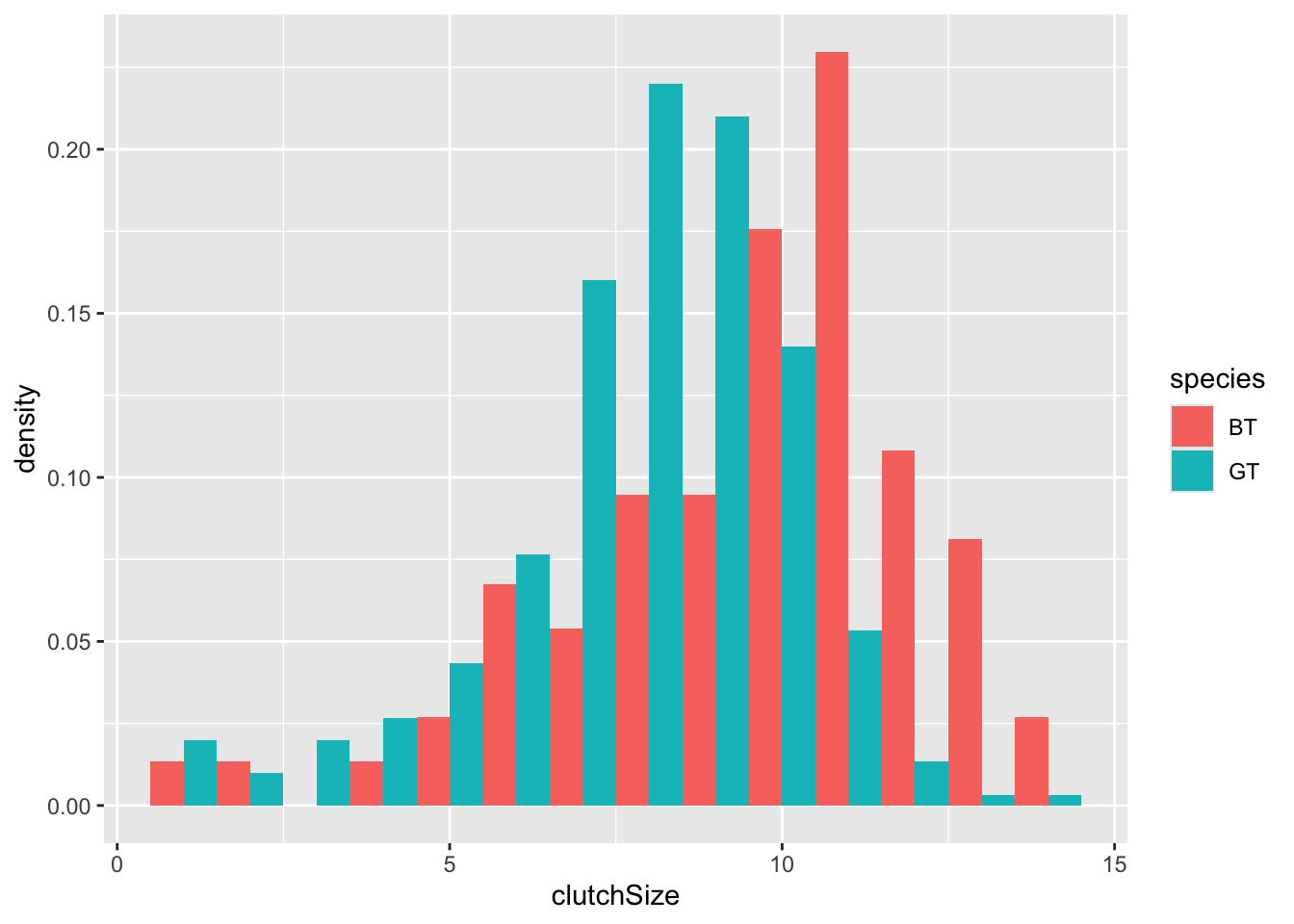
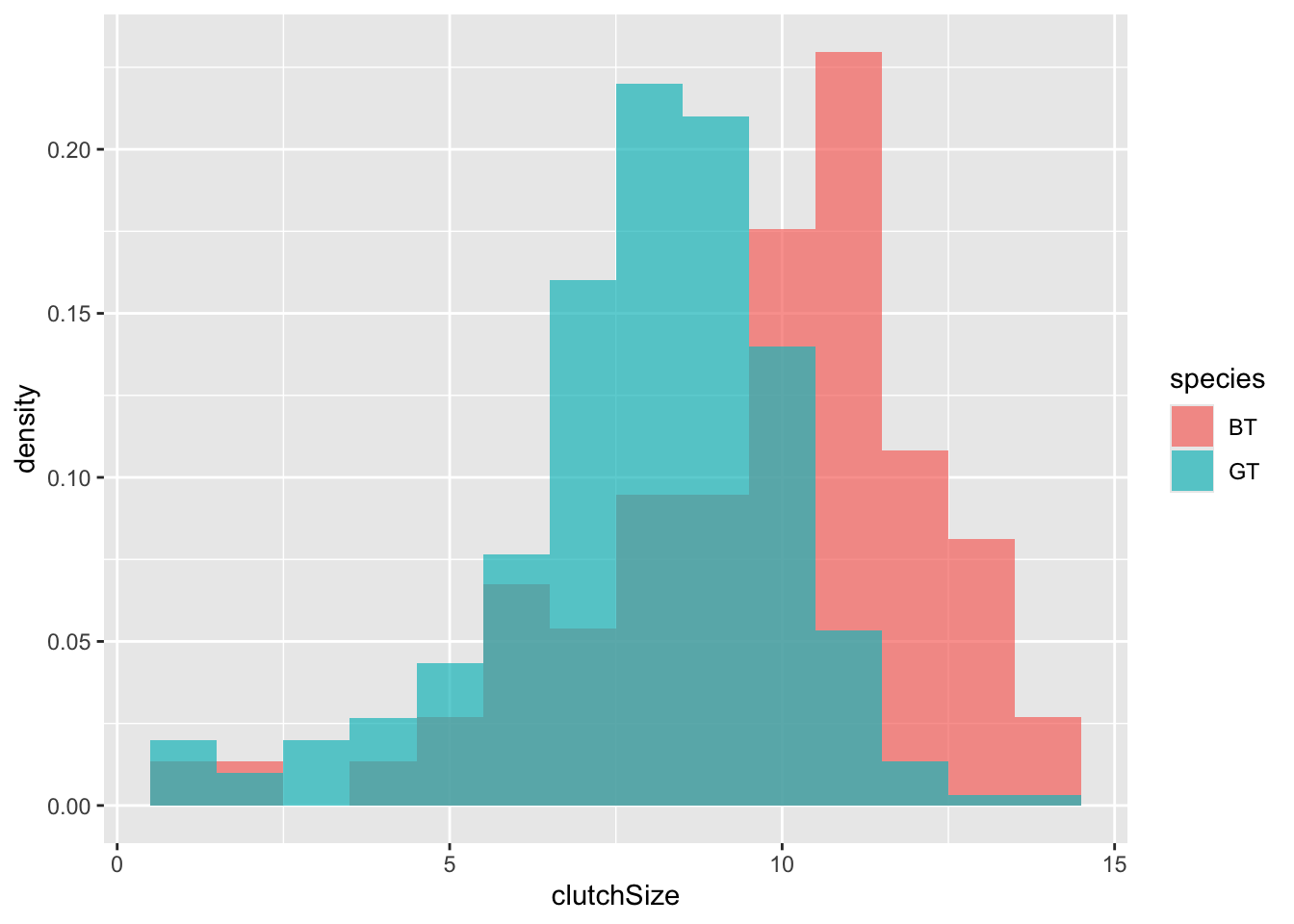
Try this: Switch to densities so the shapes are comparable:
clutch %>%
ggplot(aes(x = clutchSize, fill = species, y = after_stat(density))) +
geom_histogram(binwidth = 1, position = "identity", alpha = 0.7)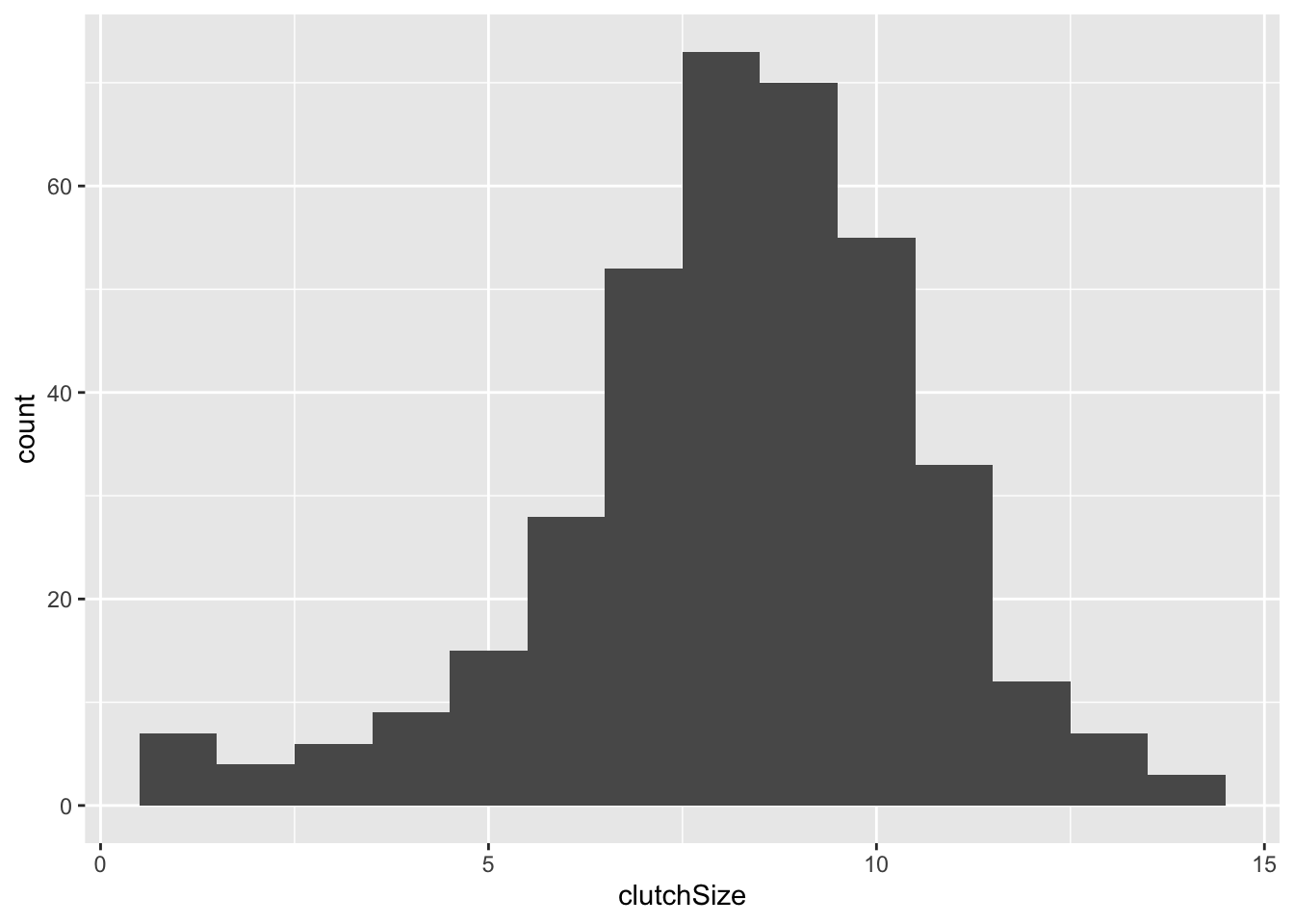
Takeaway: Use densities when sample sizes differ.
10.4 Facets (split across panels)
What we’re about to do: We will split plots by year so each year gets its own panel.
clutch %>%
ggplot(aes(x = clutchSize, fill = species, y = after_stat(density))) +
geom_histogram(binwidth = 1, position = "identity", alpha = 0.7) +
facet_grid(. ~ Year)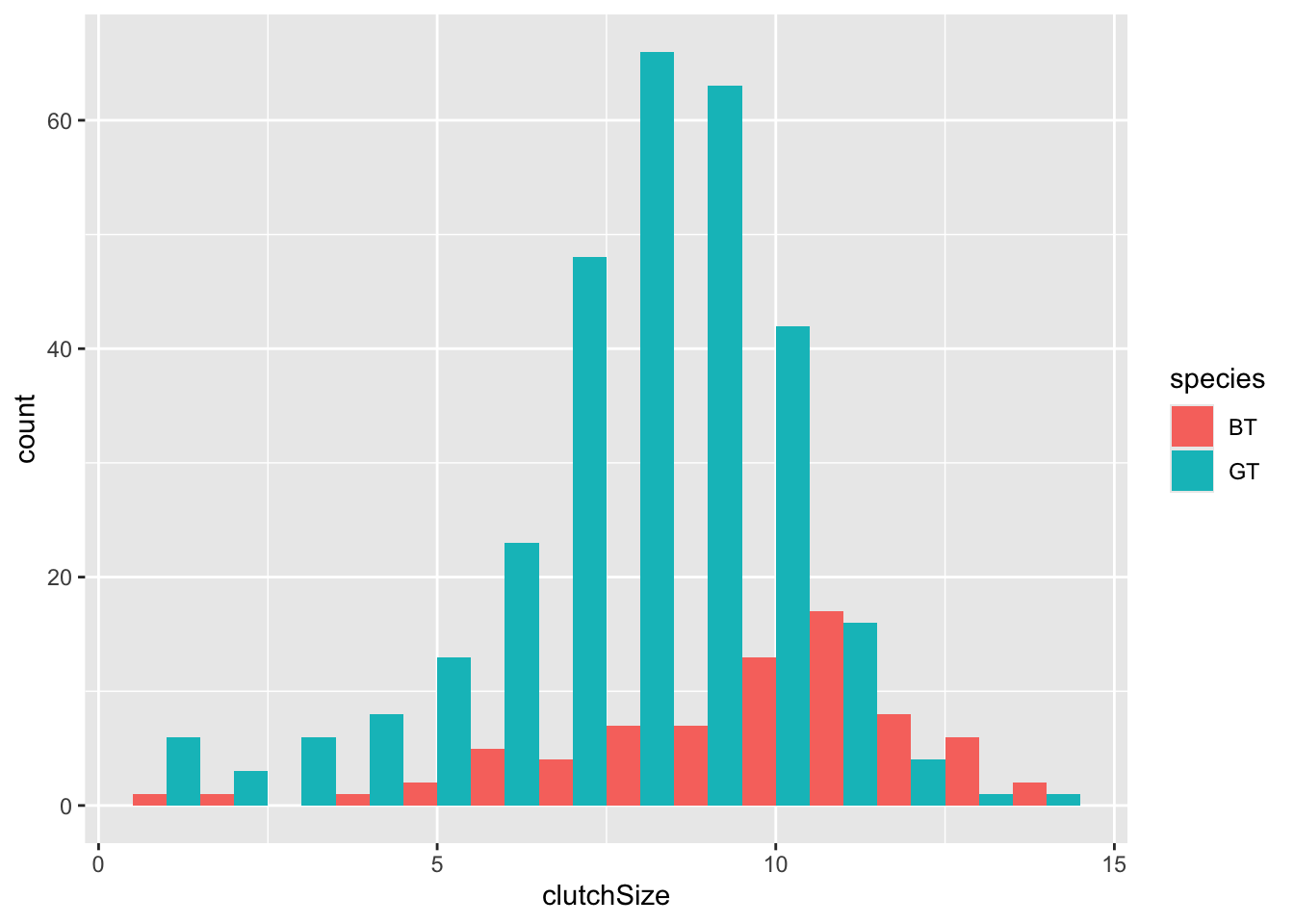
What just happened: Each year is shown in a separate panel. This makes year-to-year differences easier to see.
- What to look for:
- Does the distribution shift over time?
- Are some years more variable than others?
Try this: Flip the facet so species are rows:
Takeaway: Facets let you compare groups without overplotting.
10.5 Box plots
What we’re about to do: We will compare clutch size between species using box plots.
What just happened: The box shows the middle 50% of values; the line is the median.
- What to look for:
- Are medians different between species?
- Are spreads similar or very different?
Try this: Add jittered points for transparency.
clutch %>%
ggplot(aes(x = species, y = clutchSize)) +
geom_boxplot() +
geom_jitter(width = 0.2, alpha = 0.5)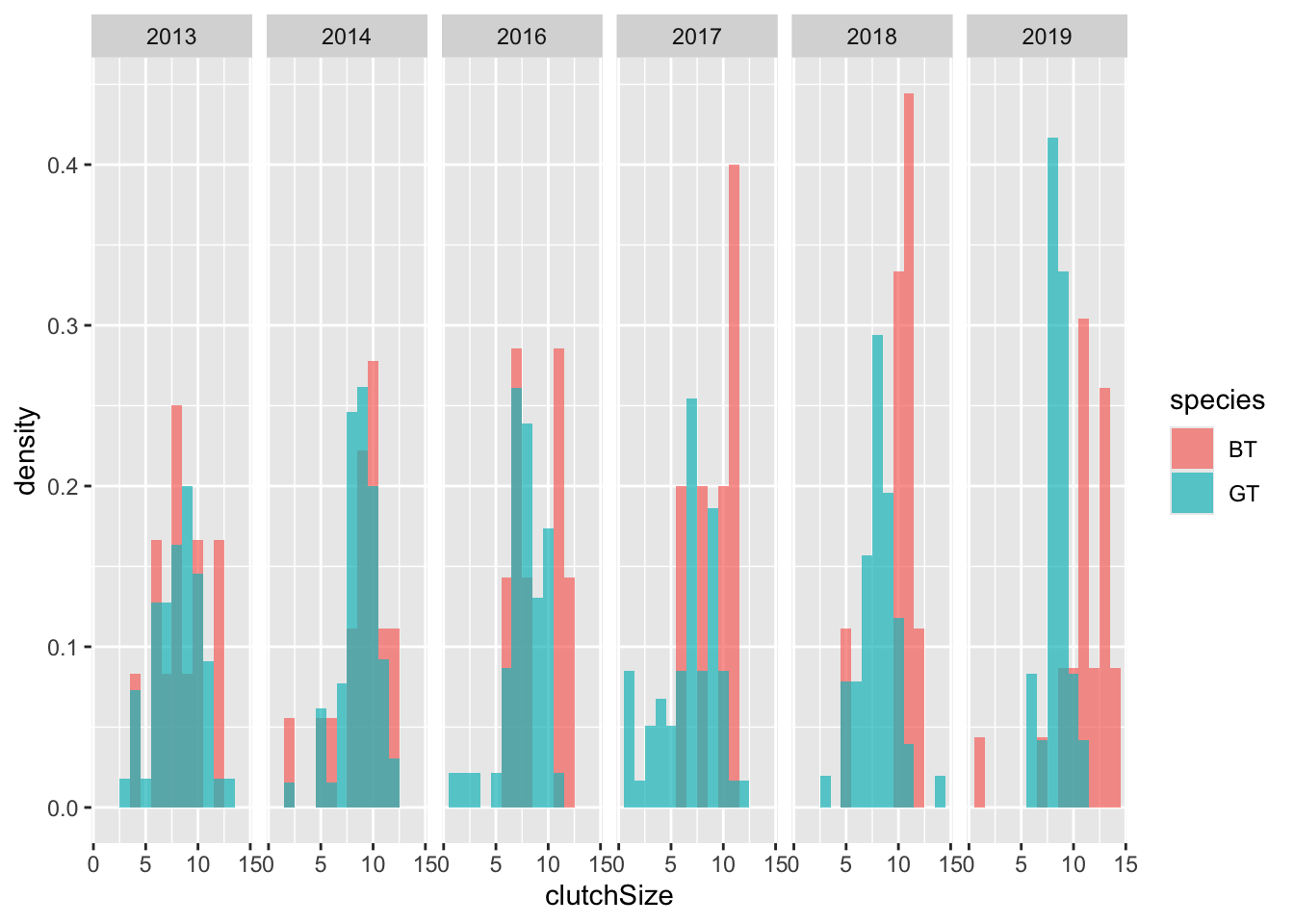
Common mistake: If your points overlap too much, increase width or reduce alpha.
Takeaway: Box plots are usually better than bar plots for comparing distributions.
10.6 Lines and points (trends over time)
What we’re about to do: We will summarise clutch size by year and plot a time trend.
mean_clutch <- clutch %>%
group_by(species, Year) %>%
summarise(mean_clutch_size = mean(clutchSize), .groups = "drop")mean_clutch %>%
ggplot(aes(x = Year, y = mean_clutch_size, colour = species)) +
geom_line() +
geom_point() +
ylim(0, 14) +
ylab("Mean clutch size") +
ggtitle("Clutch size data from SDU campus")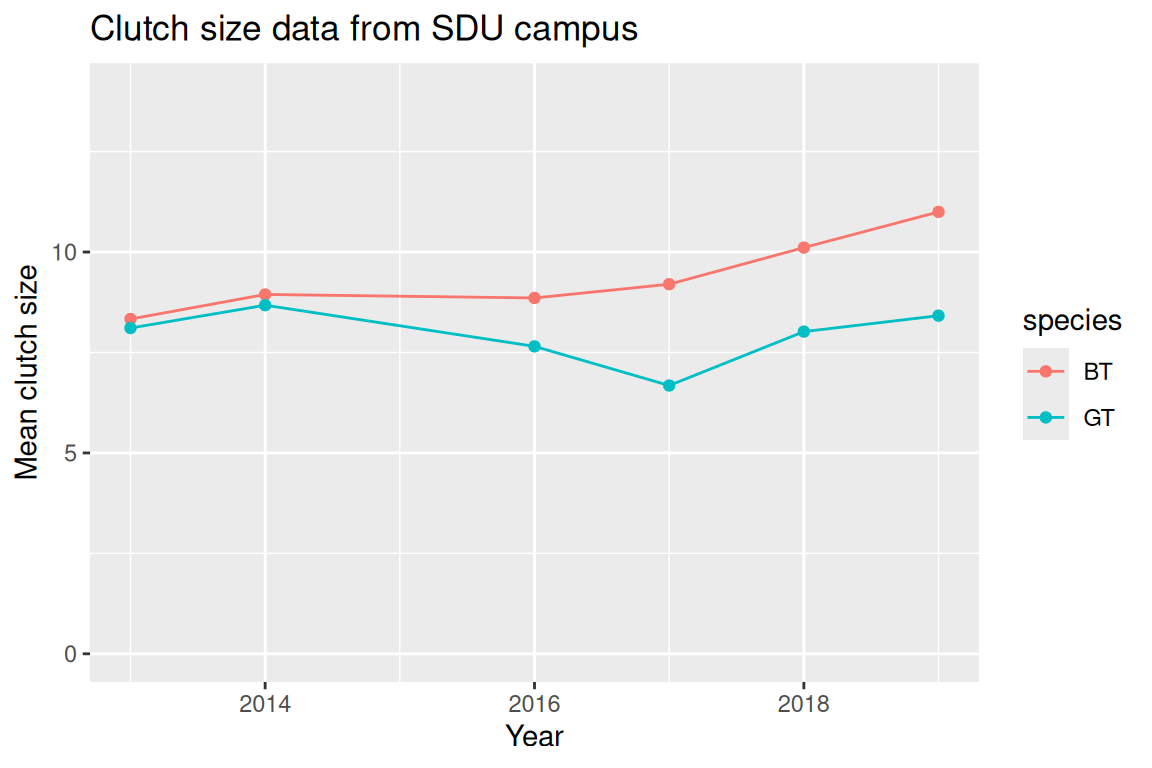
What just happened: Each point is a year’s mean clutch size; lines connect years.
- What to look for:
- Do the two species move together or differently?
- Are there years that stand out?
Caution: A mean hides variability. For deeper analysis, check sample sizes or plot distributions per year.
Takeaway: Lines are good for ordered values like time.
10.7 Scatter plots
What we’re about to do: We will plot how bird species richness changes with suburb age.
birds %>%
ggplot(aes(x = Age, y = nSpecies)) +
geom_point() +
ylim(0, 15) +
xlab("Age of development") +
ylab("Bird species richness")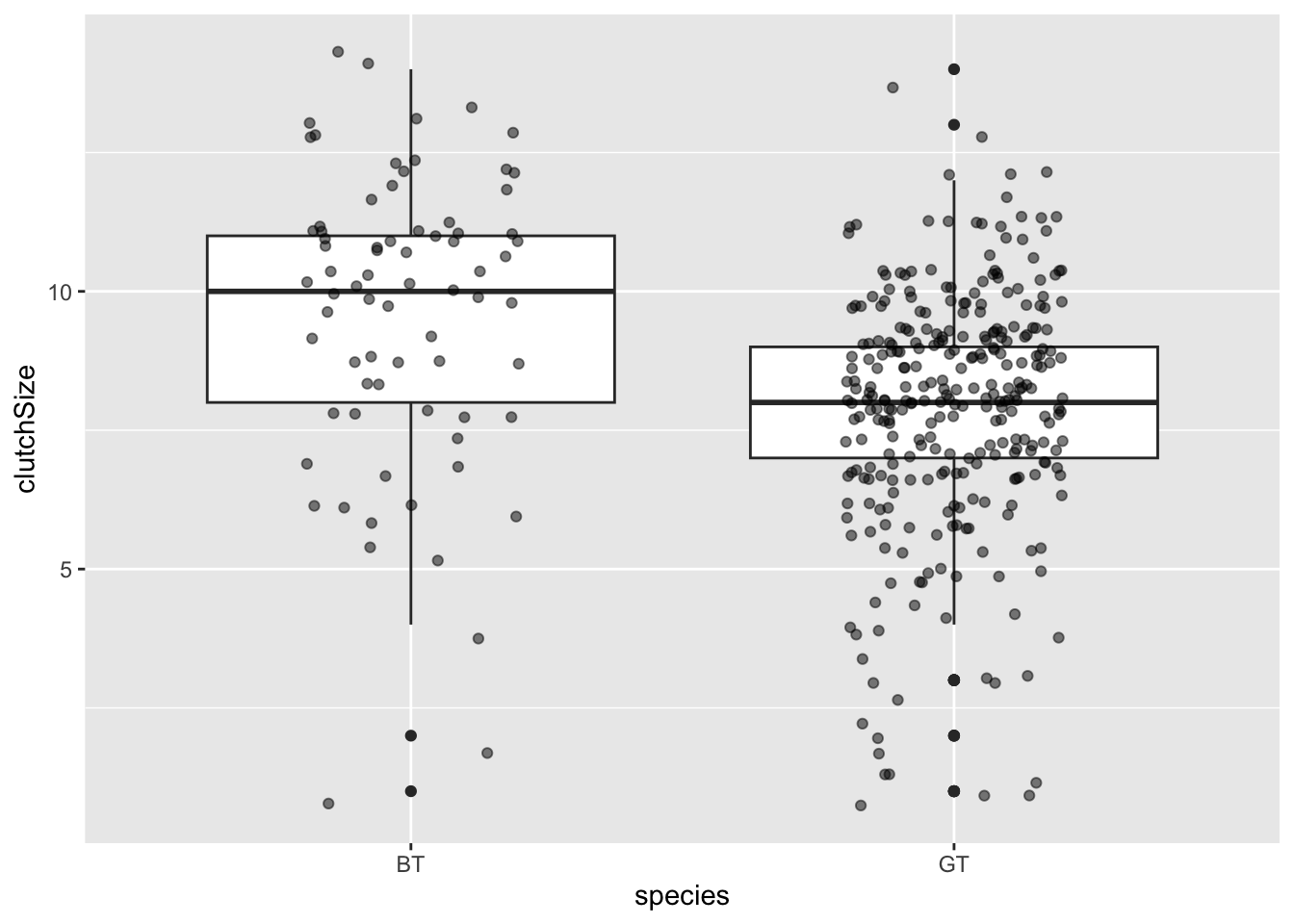
What just happened: Each point is a suburb. The plot shows older suburbs tend to have more species.
- What to look for:
- Is the relationship roughly linear or does it level off?
- Are there outliers that might drive the pattern?
Try this: Add a smooth trend line with geom_smooth() and see if the relationship looks curved.
Takeaway: Scatter plots are the starting point for relationship questions.
10.8 Bar plots (use with care)
What we’re about to do: We will see why bar plots can be misleading and when they are acceptable.
Bar charts can hide the shape of data. They are fine for counts, but risky for means.
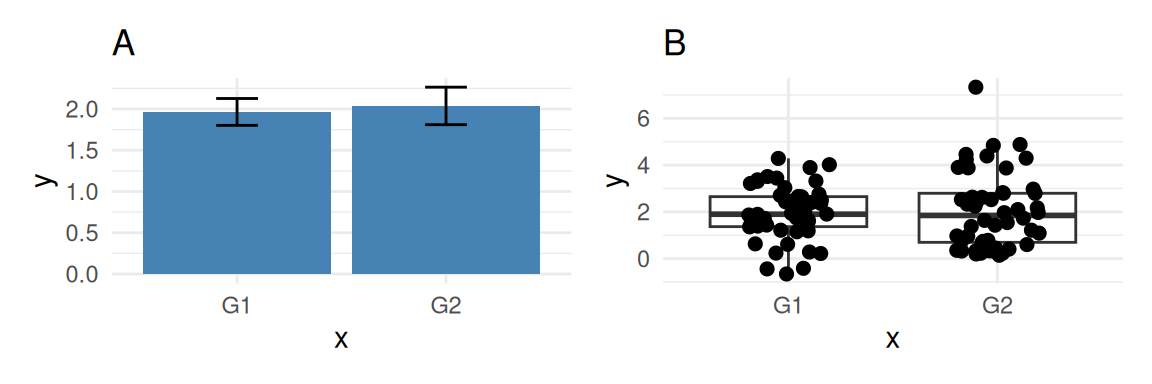
Figure 10.1: Problems with bar plots.
Interpretation: The bar plot hides the skew and outliers visible in the box plot.
- What to look for:
- How much information disappears when you only show the mean?
When bar plots are OK: Counts are a good example.
clutch %>%
count(species, name = "sample_size") %>%
ggplot(aes(x = species, y = sample_size)) +
geom_bar(stat = "identity") +
labs(title = "Sample sizes by species", x = "Species", y = "Sample size")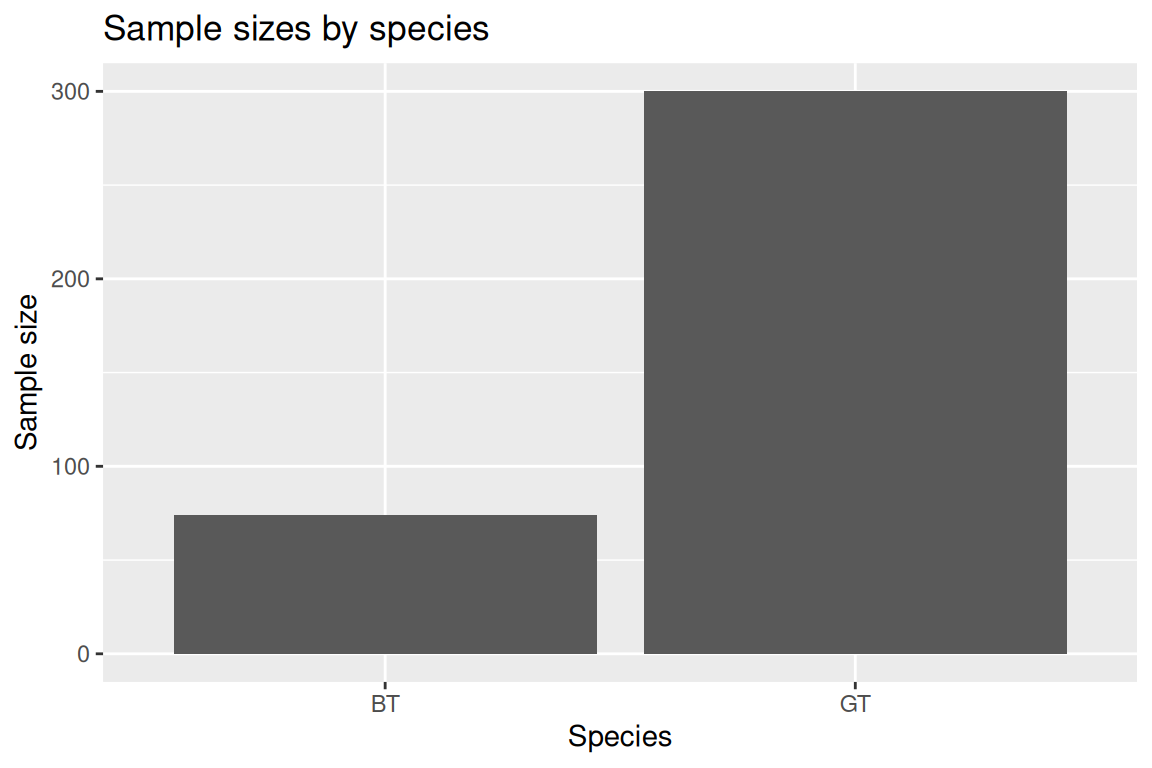
Try this: Plot counts by year and compare a bar plot to a line plot. Which tells the story more clearly?
Takeaway: Use bar plots for counts, not for means.
10.9 Key takeaways
ggplot(data, aes(...)) + geom_*()is the core pattern.- Use histograms and box plots to understand distributions.
- Use facets to compare groups without clutter.
- Use lines and points for ordered data like time.
- Use bar plots mainly for counts.
10.10 Common pitfalls recap
- Mapping the wrong variable to
xory(check youraes()call). - Forgetting
geom_*()(you’ll get an empty plot). - Using bar plots for means without showing the distribution.
10.11 Mini-project
Choose one dataset from CourseData and produce three plots:
- A distribution plot (histogram or box plot).
- A relationship plot (scatter or line).
- A grouped comparison (facets or colour).
Write 2–3 sentences under each plot describing what it shows and one thing you would check next.