Chapter 8 Data wrangling with dplyr
This chapter focuses on the package dplyr, which is designed to make working with data in R easier.
The package has several key “workhorse” functions, sometimes called verbs. These are: filter, select, mutate, arrange and summarise. I covered these in the lecture, and they are also discussed in the textbook. This chapter guides you through worked examples to illustrate their use.
We will also be using pipes from the magrittr package, implemented using the command %>%.
To get to know dplyr and its functions we’ll use a data set collected from the University of Southern Denmark (SDU) campus. The SDU bird project follows the fate of mainly great tits (musvit) and blue tits (blåmejse) in about 100 nest boxes in the woods around the main SDU campus.
We will address two questions concerning clutch size (the number of eggs laid into the nest):
- How does clutch size differ between blue tits and great tits?
- How does average clutch size vary among years?
To answer these questions we need to calculate the average clutch size (number of eggs) for each nest in each year. The data are in a file called sduBirds.csv and are raw data collected while visiting the nests. The data will need to be processed to answer those questions.
Let’s import the data and take a look at it. Make sure your data looks OK before moving on.
You should first set up your working directory (e.g. a folder for the course, with a sub-folder for course data), and set it with setwd().
See the earlier material for how to do this, or ask for help.
## 'data.frame': 9357 obs. of 15 variables:
## $ Timestamp : chr "2013-05-14" "2013-05-03" "2013-06-25" "2013-06-18" ...
## $ Year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
## $ Day : int 134 123 176 169 112 112 116 183 143 107 ...
## $ boxNumber : int 1 1 1 1 1 1 1 1 1 1 ...
## $ species : chr "BT" "BT" "BT" "BT" ...
## $ stage : chr "NL" "NL" "NE" "NE" ...
## $ nEggs : int 12 8 0 0 0 0 0 0 NA 0 ...
## $ nLiveChicks: int 0 0 0 0 0 0 0 0 0 0 ...
## $ nDeadChicks: int 0 0 0 0 0 0 0 0 0 0 ...
## $ eggStatus : chr "WA" "CO, CV" NA NA ...
## $ chickStatus: chr NA NA NA NA ...
## $ adultStatus: chr "FN" "FN" NA NA ...
## $ finalStatus: chr NA NA "NE" "NE" ...
## $ Comments : chr NA "MA" NA NA ...
## $ observerID : chr "AMK" "AMK" "AMK" "AMK" ...8.1 select
From the str summary (above) you can see that there are many columns in the data set and we only need some of them. Let’s select only the columns that we need for our calculations to make things a bit easier to handle. We need the species, Year, Day, boxNumber and nEggs:
## species Year Day boxNumber nEggs
## 1 BT 2013 134 1 12
## 2 BT 2013 123 1 8
## 3 BT 2013 176 1 0
## 4 BT 2013 169 1 0
## 5 BT 2013 112 1 0
## 6 BT 2013 112 1 0The output of head shows you the first few rows of the data set. Each row represents a visit to a particular nest. The researcher records the bird species if it is known (GT = Great tit, BT = Blue tit, NH = Nuthatch etc.), and then records the number of eggs, number of chicks, activity of the adults and so on. We need to convert this large dataset into one that contains clutch size for each nest, for each year of the study.
The information given by str (above) shows that there are data on species other than our target species. We are only interested in the great tits and blue tits so we can first filter the others out using the species variable.
We can check the make-up of this part of the data using the table function, which counts the entries.
##
## BT GT MT NH WR
## 992 4612 73 31 58.2 filter
Now let’s filter this data and double check that this has worked:
##
## BT GT
## 992 46128.3 arrange
Recall that the data are records of visits to each nest a few times per week. To ensure that the data are in time order we can arrange by Year and then Day. To illustrate this we can make a temporary data set (called temp) to look at a particular nest in a particular year, and then plot it (this is an ugly plot and we will learn how to make beautiful ones soon):
sduBirds <- arrange(sduBirds, Year, Day)
temp <- filter(sduBirds, boxNumber == 1, Year == 2014)
max(temp$nEggs) # get the max value## [1] 12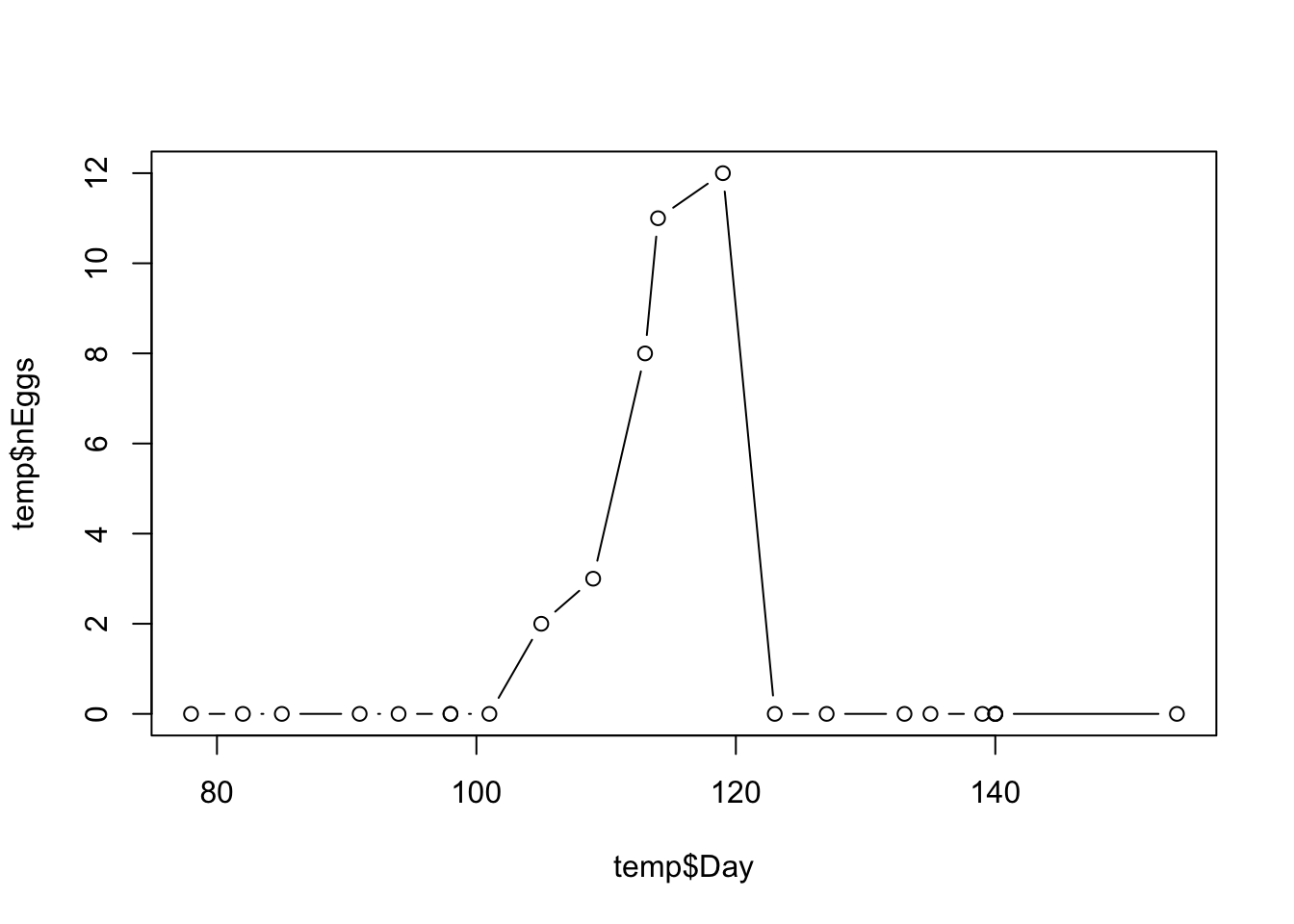
Eggs are usually laid one per day, and the clutch size is the maximum number of eggs reached for each nest box. In this case, the clutch size is 12 eggs. The rapid decline in number of eggs after this peak value shows when the eggs have hatched and the researcher finds chicks instead of eggs.
8.4 summarise and group_by
The next part is the crucial part of our investigation. We need to get the maximum number of eggs seen at each nest. Of course we could repeatedly use filter, followed by max, for each nest-year combination but this would be incredibly tedious.
Instead, we will use the dplyr function summarise to do this by asking for the maximum value of nEggs using max. To make this work we first need to use the group_by function to tell R to group the data by the variables we are interested in. If we don’t do this we just get the overall maximum. We can ungroup the data using the ungroup function.
Because there are missing data (NA values) we need to specify na.rm = TRUE in the argument.
So first, let’s get the max per species, just to illustrate how this works:
## # A tibble: 2 × 2
## species clutchSize
## <chr> <int>
## 1 BT 14
## 2 GT 14We can see how the data are grouped by using the groups function:
## [[1]]
## speciesWe can ungroup the data again like this:
So both species lay the same maximum number of eggs, but maybe this is just caused by outliers for one of the species. We’ll need to dig deeper.
How can we calculate the average? We cannot simply ask for the mean because the data run through time following the development in each nest. We need to calculate the maximum nEggs for each nest, and then calculate the average of those. We can do this in two steps.
We calculate the clutch size as the maximum (max) number of eggs in each box, for each species, in each year. A warning message appears because R attempts to calculate the maximum number of eggs for all combinations of species, year, and box number, but some of these combinations contain no data (i.e., all NA values), making it impossible to compute a maximum. This warning can be safely ignored in this case.
sduBirds <- group_by(sduBirds, species, Year, boxNumber)
sduBirds <- summarise(sduBirds, clutchSize = max(nEggs, na.rm = TRUE))Let’s first look at all the clutch size data:
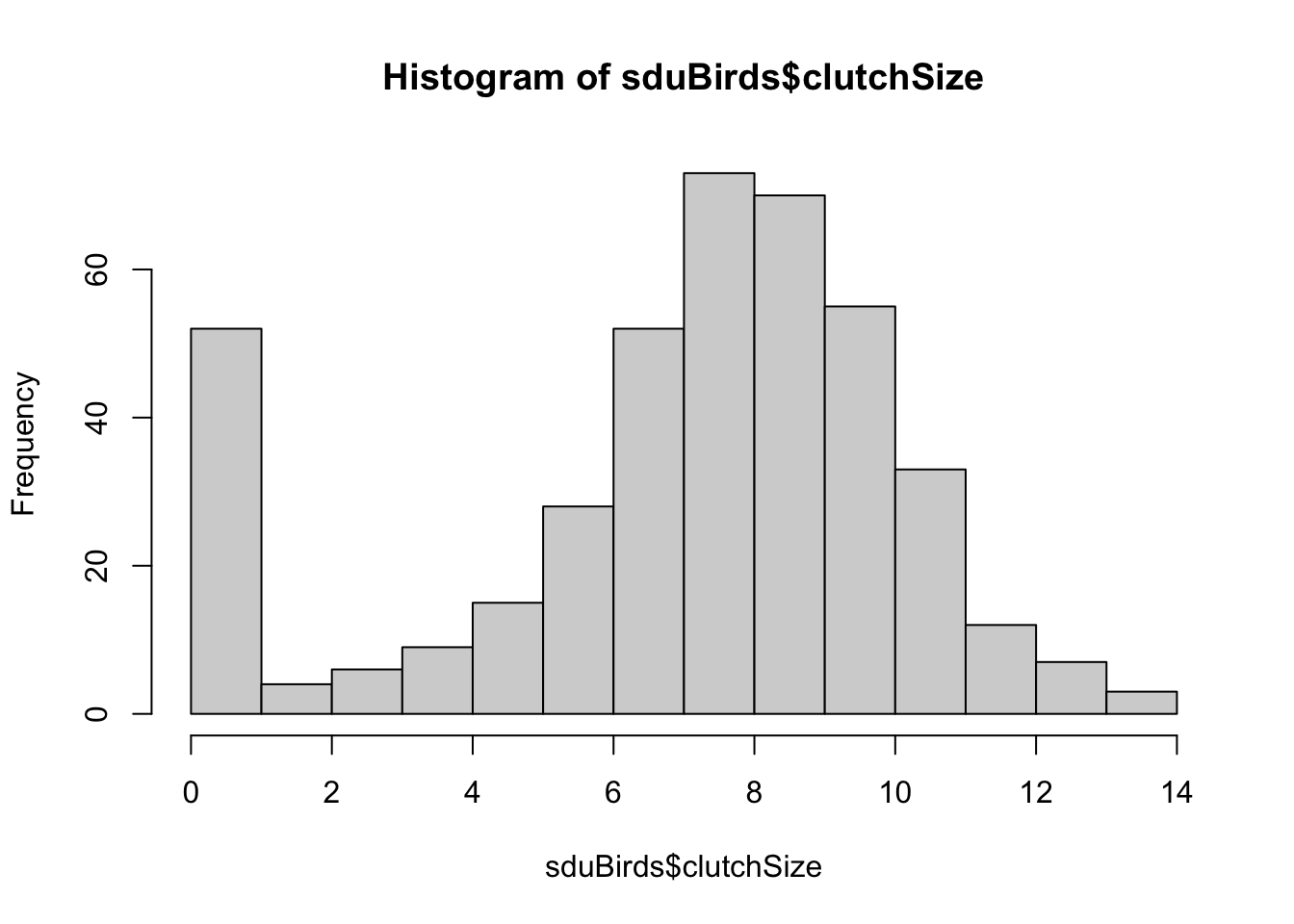
You can see here that there are a lot of zero values. This is because nests were recorded even if they did not attempt to lay eggs. We should remove these from our data using filter again:
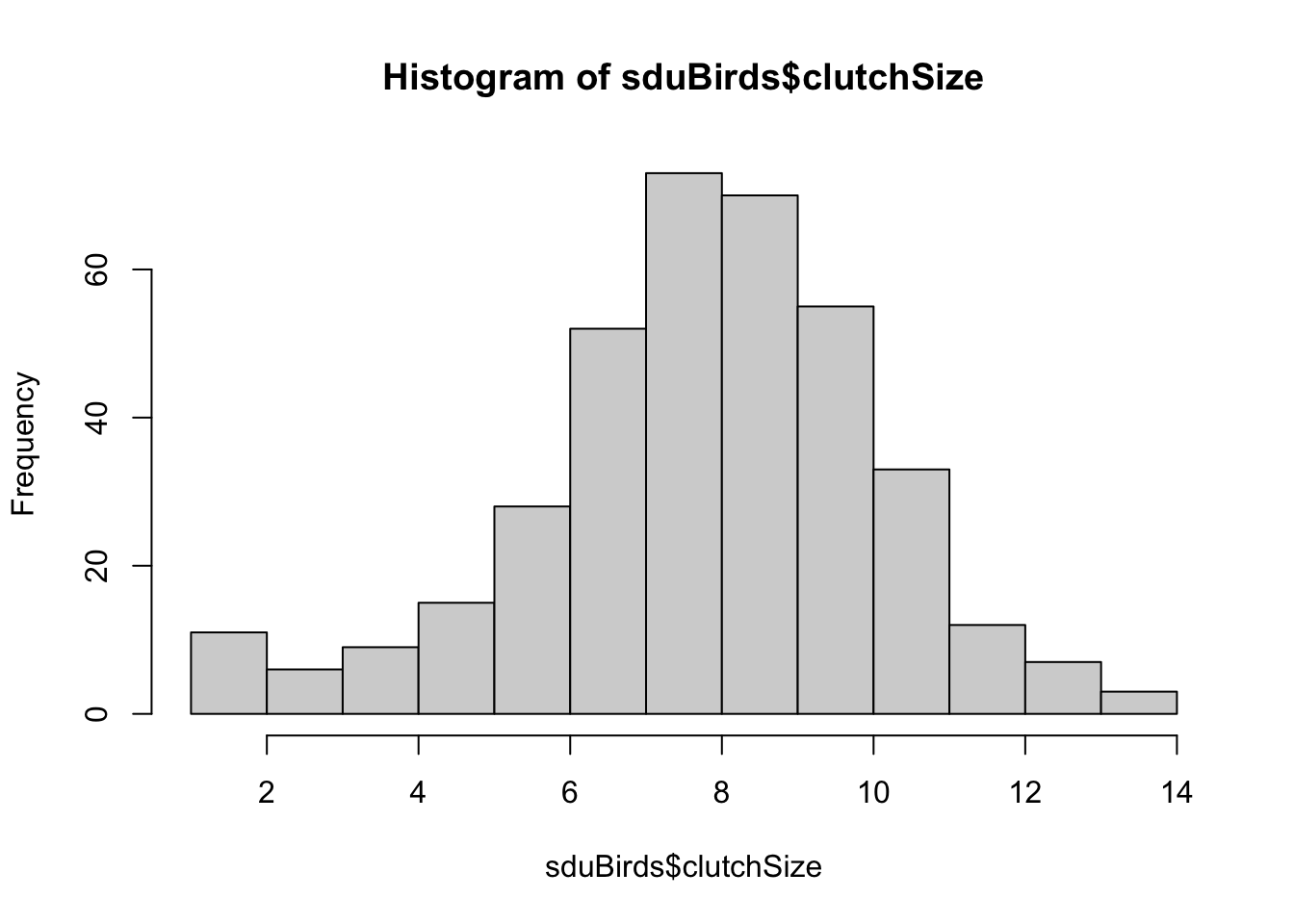
That looks better.
Now we can plot them again but this time split apart the species (again - this plot is ugly and we’ll learn to plot nicer ones soon).
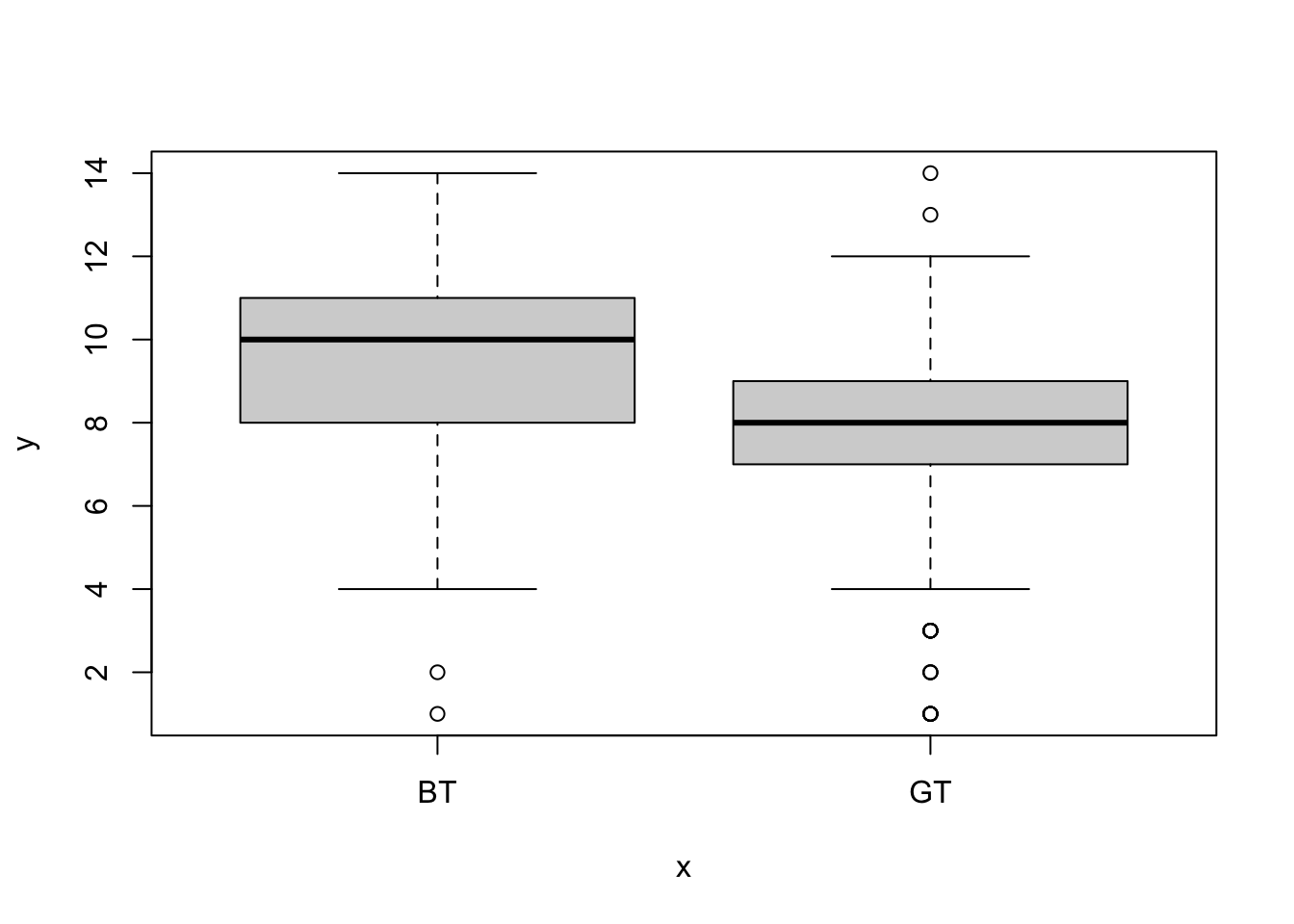
From these distributions it looks like the average clutch size is greater in the blue tit. We can use summarise to calculate the means.
sduBirds <- group_by(sduBirds, species)
summarise(sduBirds, mean = mean(clutchSize), sd = sd(clutchSize))## # A tibble: 2 × 3
## species mean sd
## <chr> <dbl> <dbl>
## 1 BT 9.64 2.64
## 2 GT 7.89 2.19Lets now turn to the other question - how does the clutch size vary with year?
sduBirds <- group_by(sduBirds, species, Year)
sduBirds2 <- summarise(sduBirds, meanClutchSize = mean(clutchSize))
head(sduBirds2)## # A tibble: 6 × 3
## # Groups: species [1]
## species Year meanClutchSize
## <chr> <int> <dbl>
## 1 BT 2013 8.33
## 2 BT 2014 8.94
## 3 BT 2016 8.86
## 4 BT 2017 9.2
## 5 BT 2018 10.1
## 6 BT 2019 11We can plot this by first making a plot for blue tits, and then adding the points for great tits. I have used the pch argument to use filled circles for the great tits:
plot(sduBirds2$Year[sduBirds2$species == "BT"],
sduBirds2$meanClutchSize[sduBirds2$species == "BT"],
type = "b",
ylim = c(0, 12), xlab = "Year", ylab = "Clutch Size"
)
points(sduBirds2$Year[sduBirds2$species == "GT"],
sduBirds2$meanClutchSize[sduBirds2$species == "GT"],
pch = 16, type = "b"
)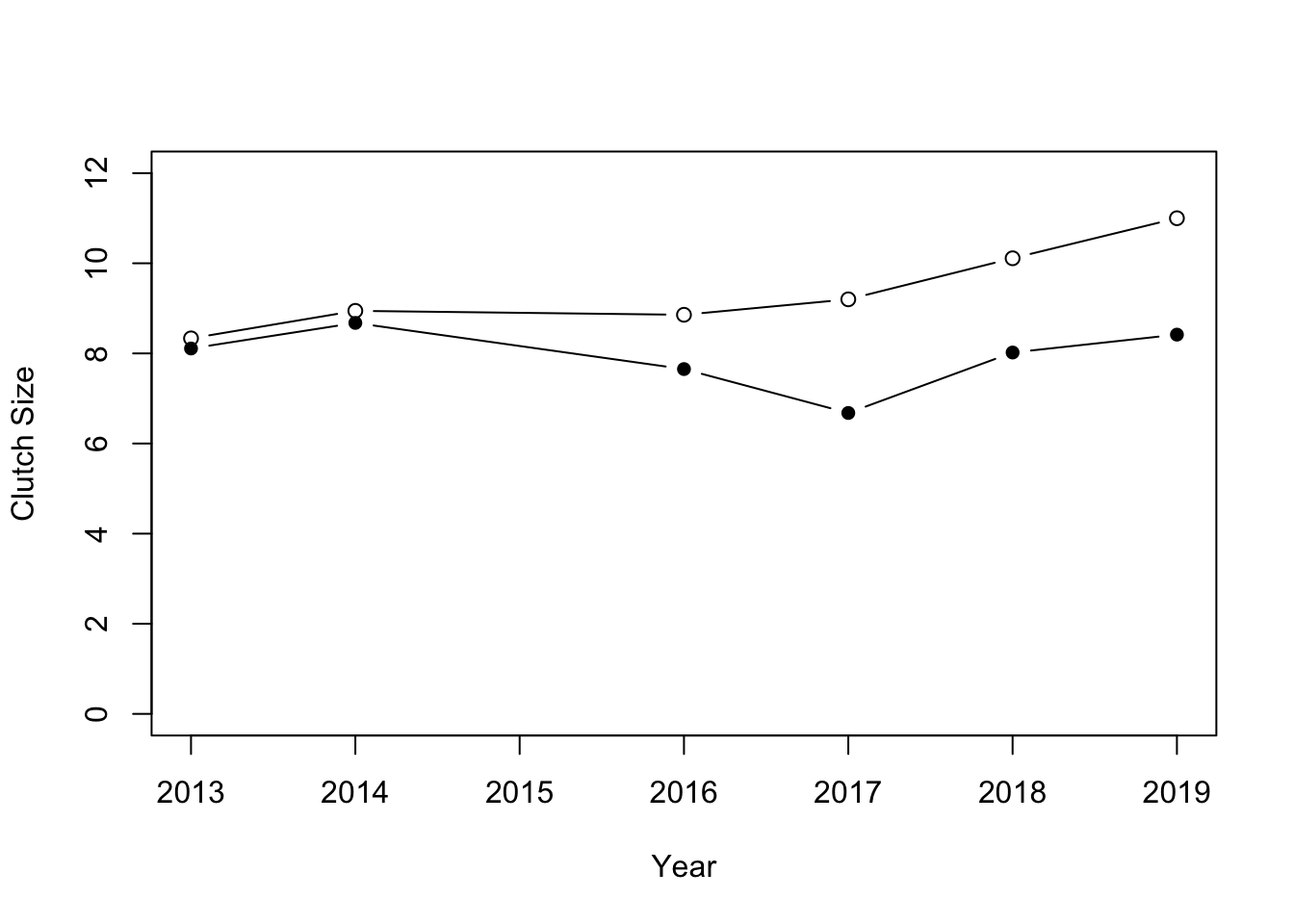
So it looks like the clutch size varies a fair amount from year to year, but that generally blue tits have larger clutch sizes than great tits.
This approach of using group_by followed by summarise can be used to summarise data in many different ways: maximum or minimum value (max or min), variance or standard deviation (var or sd), quantiles such as the 10% or 50% quantile (see the section on Distributions below) (quantile), cumulative sums (cumsum) or counts (n or length) and so on.
| Command | What |
|---|---|
| min(x) | minimum value |
| max(x) | maximum value |
| n() | number of records, see ?n |
| length(x) | number of records |
| var(x) | variance |
| sd(x) | std. devation |
| quantile(x,y) | a quantile, e.g. quantile(x, 0.25) |
8.5 Using pipes, saving data.
I have walked you through a step-by-step data manipulation. During that process you made (and replaced) new data sets at each step. In practice this can be done more smoothly using pipes (%>%) to pass the result of one function into the next, and the next, and the next…
You’ll get more practice with this as we go on. Below I show how to do this to create a clutch size data set from the raw data (note that your file path will differ from mine):
# Import and process data using pipes
SDUClutchSize <- read.csv("CourseData/sduBirds.csv") %>%
filter(species %in% c("GT", "BT")) %>% # include only GT and BT
select(species, Year, Day, boxNumber, nEggs) %>% # select columns
group_by(species, Year, boxNumber) %>% # group data
summarise(clutchSize = max(nEggs, na.rm = TRUE)) %>% # clutch size
filter(clutchSize > 0)
head(SDUClutchSize)## # A tibble: 6 × 4
## # Groups: species, Year [1]
## species Year boxNumber clutchSize
## <chr> <int> <int> <dbl>
## 1 BT 2013 1 12
## 2 BT 2013 5 8
## 3 BT 2013 27 10
## 4 BT 2013 31 6
## 5 BT 2013 35 10
## 6 BT 2013 37 8You can save this out using the write.csv function. You will need to set the argument row.names = FALSE to stop the data including row names.
8.6 Exercise: Wrangling the Amniote Life History Database
In this exercise the aim is to use the “Amniote Life History Database” 3 to investigate some questions about life history evolution.
The questions are: (1) what are the records and typical life spans in different taxonomic classes? [what is the longest, shortest and median life span in birds, mammals and reptiles?] (2) is there a positive relationship between body mass and life span? [do big species live longer than small ones?]; (3) is there a trade-off between reproductive effort and life span? [do species that reproduce a lot have short lives, so there is a negative relationship between reproduction and life span?]; (4) is this trade-off universal across all Classes? [does the trade-off exist in birds, reptiles and amphibians?]
The database is in a file called Amniote_Database_Aug_2015.csv in the course data folder. The missing values (which are normally coded as NA in R) are coded as “-999”. The easiest way to take care of this is to specify this when we import the data using the na.strings argument of the read.csv function. Thus we can import the data like this:
Let’s make a start…
When you have imported the data, use
dimto check the dimensions of the whole data frame (you should see that there are 36 columns and 21322 rows). Usenamesto look at the names of all columns in the data inamniote.We are interested in longevity (lifespan) and body size and reproductive effort and how this might vary depending on the taxonomy (specifically, with Class). Use
selectto pick relevant columns of the dataset and discard the others. Call the new data framex. The relevant columns are the taxonomic variables (class,genus&species) andlongevity_y,litter_or_clutch_size_n,litters_or_clutches_per_y, andadult_body_mass_g.Take a look at the first few entries in the
speciescolumn. You will see that it is only the epithet, the second part of the Genus_species name, that is given.
Usemutateandpasteto convert thespeciescolumn to a Genus_species by pasting the data ingenusandspeciestogether. To see how this works, try out the following command,paste(1:3, 4:6). After you have created the new column, remove thegenuscolumn (usingselectand-genus).What is the longest living species in the record? Use
arrangeto sort the data from longest to shortest longevity (longevity_y), and then look at the top of the file usingheadto find out. (hint: you will need to use reverse sort (-)). Cut and paste the species name into Google to find out more!Do the same thing but this time find the shortest lived species.
Use
summariseandgroup_byto make a table summarisingmin,medianandmaxlife spans (longevity_y) for the three taxonomic classes in the database. Remember that you need to tell R to remove theNAvalues using ana.rm = TRUEargument.Body size is thought to be associated with life span. Let’s treat that as a hypothesis and test it graphically. Sketch what would the graph would look like if the hypothesis were true, and if it was false. Plot
adult_body_mass_gvs.longevity_y(using base R graphics). You should notice that this looks a bit messy.Use
mutateto create newlog-transformed variables,logMassandlogLongevity. Use these to make a “log-log” plot. You should see that makes the relationship more linear, and easier to “read”.Is there a trade-off between reproductive effort and life span? Think about this as a hypothesis - sketch what would the graph would look like if that were true, and if it was false. Now use the data to test that hypothesis: Use
mutateto create a variable calledlogOffspringwhich is the logarithm of number of litters/clutches per year multiplied by the number of babies in each litter/clutch . Then plotlogOffspringvs.logLongevity.To answer the final question (differences between taxonomic classes) you could now use
filterto subset to particular classes and repeat the plot to see whether the relationships holds universally.
Remember that if you struggle you can check back to previous work where you have used dplyr commands to manipulate data in a similar way. If you get truly stuck, ask for help from instructors or fellow students.