Chapter 9 Combining data sets
Handling data is often not limited to single data sets. One common task is to combine two (or more) data sets. For example, one data set might include observations from a field study, while another might have information about the weather during the study period or site-specific information. It is therefore useful to be able to combine these data sets to add information from the second table to the first.
R does this with the dplyr function join. In the next section you will first learn how join works by following an example that asks a research question that can only be answered by combining two data sets. After that, you will work on your own to do a similar analysis without explicit instructions (i.e. you will need to figure out how to apply the method to new data).
9.1 Using join
By following this example you will learn how to combine two data sets to create a new data set for a conservation-related question: “Does threat status vary with species’ generation times?”
This question is crucial to conservation biologists because it helps us generalise our ideas about what drives extinction risk. In other words, if we can say “species with slow life histories tend to be more threatened”, that gives useful information for planning. For example, imagine we have some species that have not yet been assessed (we don’t know if they are threatened or not). Should we focus attention on the one with a short generation time, or the one with a long generation time?
To answer the question we will need to import two large data sets, tidy them up a bit, and then combine them for analysis.
Let’s start with the “Amniote Life History Database” 4, which is a good source of life history data. We have encountered this database before. Recall that the missing values (which are normally coded as NA in R) are coded as “-999”. The easiest way to take care of this is to specify this when we import the data using the na.strings argument of the read.csv function. Thus we can import the data like this:
We can filter on the taxonomic class to subset to mammals. Then, to address our question, we want data on generation time for mammals. Generation time is often measured as the average age at which females reproduce, so we can get close to that with female_maturity_d. We will first select these columns, along with genus and species. We can combine these two taxonomic variables using mutate and paste to get our Latin binomial species name.
We have previously learned that log transforming such variables is useful, so we can use mutate again to do this transformation.
Finally, we can use na.omit to get rid of entries with missing values (which we cannot use). This is not essential, but keeps things more manageable.
mammal <- amniote %>%
filter(class == "Mammalia") %>%
# get the mammals only
select(genus, species, female_maturity_d) %>%
# get useful columns
mutate(species = paste(genus, species)) %>%
select(-genus) %>%
mutate(logMaturity = log(female_maturity_d)) %>%
na.omit()Let’s take a quick look at what we have:
## species female_maturity_d logMaturity
## 20 Echinops telfairi 278.42000 5.629131
## 22 Hemicentetes nigriceps 48.57000 3.883006
## 23 Hemicentetes semispinosus 46.19892 3.832956
## 27 Microgale dobsoni 669.59200 6.506669
## 40 Microgale talazaci 639.00000 6.459904
## 47 Setifer setosus 198.00000 5.288267Looks good. Now let’s import the IUCN Red List data.
Let’s take a look at that.
## [1] "Species.ID" "Kingdom"
## [3] "Phylum" "Class"
## [5] "Order" "Family"
## [7] "Genus" "Species"
## [9] "Authority" "Infraspecific.rank"
## [11] "Infraspecific.name" "Infraspecific.authority"
## [13] "Stock.subpopulation" "Synonyms"
## [15] "Common.names..Eng." "Common.names..Fre."
## [17] "Common.names..Spa." "Red.List.status"
## [19] "Red.List.criteria" "Red.List.criteria.version"
## [21] "Year.assessed" "Population.trend"
## [23] "Petitioned"## [1] "DD" "LC" "CR" "NT" "EN" "VU" "EX" "EW"There’s a lot of information there but what we really need is the Latin binomial (for which we need genus and species) and the threat status Red.List.status.
R treats categorical variables (factor variables) as alphabetical, but in this case the red list status has a meaning going from low threat (Least Concern - LC) to Critically Endangered (CR) and even Extinct in the Wild (EX) at the other end of the spectrum. We can define this ordering using mutate with the factor function.
redlist <- redlist %>%
mutate(species = paste(Genus, Species)) %>%
select(species, Red.List.status) %>%
mutate(Red.List.status = factor(Red.List.status,
levels = c("LC", "NT", "VU", "EN", "CR", "EW", "EX")
))
head(redlist)## species Red.List.status
## 1 Abditomys latidens <NA>
## 2 Abeomelomys sevia LC
## 3 Abrawayaomys ruschii LC
## 4 Abrocoma bennettii LC
## 5 Abrocoma boliviensis CR
## 6 Abrocoma budini <NA>Now we can combine this with the life history data from above using left_join.
Let’s take a look at what we have now:
## species female_maturity_d logMaturity Red.List.status
## 1 Echinops telfairi 278.42000 5.629131 LC
## 2 Hemicentetes nigriceps 48.57000 3.883006 LC
## 3 Hemicentetes semispinosus 46.19892 3.832956 LC
## 4 Microgale dobsoni 669.59200 6.506669 LC
## 5 Microgale talazaci 639.00000 6.459904 LC
## 6 Setifer setosus 198.00000 5.288267 LC## species female_maturity_d logMaturity Red.List.status
## Length :2000 Min. : 23.81 Min. :3.170 LC :1219
## N.unique :2000 1st Qu.: 121.53 1st Qu.:4.800 VU : 176
## N.blank : 0 Median : 344.12 Median :5.841 EN : 168
## Min.nchar: 9 Mean : 574.92 Mean :5.745 NT : 114
## Max.nchar: 31 3rd Qu.: 696.38 3rd Qu.:6.546 CR : 66
## Max. :6391.56 Max. :8.763 (Other): 10
## NAs : 247You can see that there are 247 missing values for the Red List status. These are either species that have not yet been assessed, or cases where there are mismatches in the species names between the two databases. We will ignore this problem today.
Before plotting, I will also use filter to remove species that are extinct (status = “EX” and “EW”). To do this I use the %in% argument to match a vector of values. Because I want to NOT match them I negate the match using !.
Let’s now plot the data to answer the question.
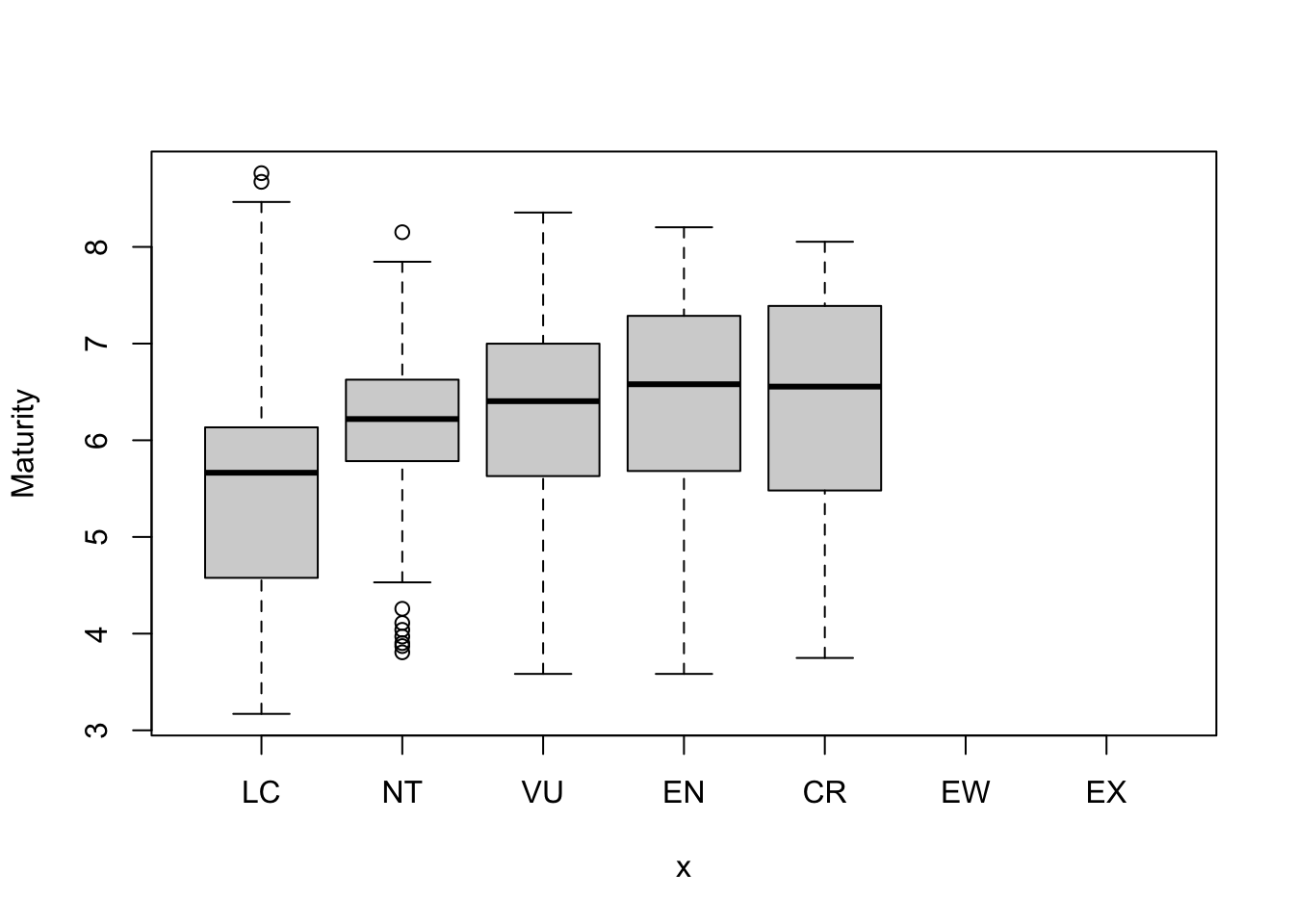
What can we see? If you focus on the median values, it looks like there is a weak positive relationship between this life history trait and threat status: animals with slower life histories tend to be more threatened.
9.2 Using pivot_longer
Sometimes data are not arranged in a way that make them easy to use in R. For example, data could be arranged so that the column headings are themselves data (e.g. treatments, sex of individuals).
To illustrate this I will use a data set on heights of men and women.
Let’s take a look:
## place heightMale heightFemale
## 1 London 170 164
## 2 London 176 158
## 3 London 179 157
## 4 London 166 158
## 5 London 177 153
## 6 London 177 155
## 7 London 173 151
## 8 London 173 155
## 9 London 173 159
## 10 London 171 158
## 11 London 173 166
## 12 London 171 156
## 13 London 172 157
## 14 London 175 159
## 15 London 179 156
## 16 Bristol 175 156
## 17 Bristol 173 156
## 18 Bristol 171 155
## 19 Bristol 172 158
## 20 Bristol 185 158
## 21 Bristol 176 153
## 22 Bristol 173 158
## 23 Bristol 173 156
## 24 Bristol 177 156
## 25 Bristol 172 159
## 26 Bristol 169 162
## 27 Bristol 177 167
## 28 Bristol 171 157
## 29 Bristol 175 166
## 30 Bristol 171 155I would like to make a boxplot, but it is not possible to easily do it with the data arranged in this format. What I need to do is “unpack” or rearrange the data to add another column for sex. This will make the data frame twice as long, and less wide.
There is a convenient function called pivot_longer in the tidyr package that will do this for you.
You can pipe data into the function, then tell it which columns you would like to move, and then give it the name of the new column that contains data that was in the column heading, and the name of the column containing the data.
newHeights <- heights %>%
pivot_longer(
cols = c(heightMale, heightFemale),
names_to = c("Sex"), values_to = "Height"
)
newHeights## # A tibble: 60 × 3
## place Sex Height
## <chr> <chr> <int>
## 1 London heightMale 170
## 2 London heightFemale 164
## 3 London heightMale 176
## 4 London heightFemale 158
## 5 London heightMale 179
## 6 London heightFemale 157
## 7 London heightMale 166
## 8 London heightFemale 158
## 9 London heightMale 177
## 10 London heightFemale 153
## # ℹ 50 more rowsWe are nearly done. But this is not perfect because the names in the Sex column are not right. We can fix this in a couple ways. Here’s one easy way using the function gsub. The gsub function (“general substitution) finds text and replaces it with other text. In this case we want to find”height” and replace it with nothing (““).
So we can now complete the job with a mutate command, and make sure it is recognised as a categorical variable (a factor), like this:
newHeights <- heights %>%
pivot_longer(
cols = c(heightMale, heightFemale),
names_to = c("Sex"), values_to = "Height"
) %>%
mutate(Sex = gsub(
pattern = "height", replacement = "",
x = Sex
)) %>%
mutate(Sex = as.factor(Sex))
newHeights## # A tibble: 60 × 3
## place Sex Height
## <chr> <fct> <int>
## 1 London Male 170
## 2 London Female 164
## 3 London Male 176
## 4 London Female 158
## 5 London Male 179
## 6 London Female 157
## 7 London Male 166
## 8 London Female 158
## 9 London Male 177
## 10 London Female 153
## # ℹ 50 more rowsNow we can plot those data more easily.
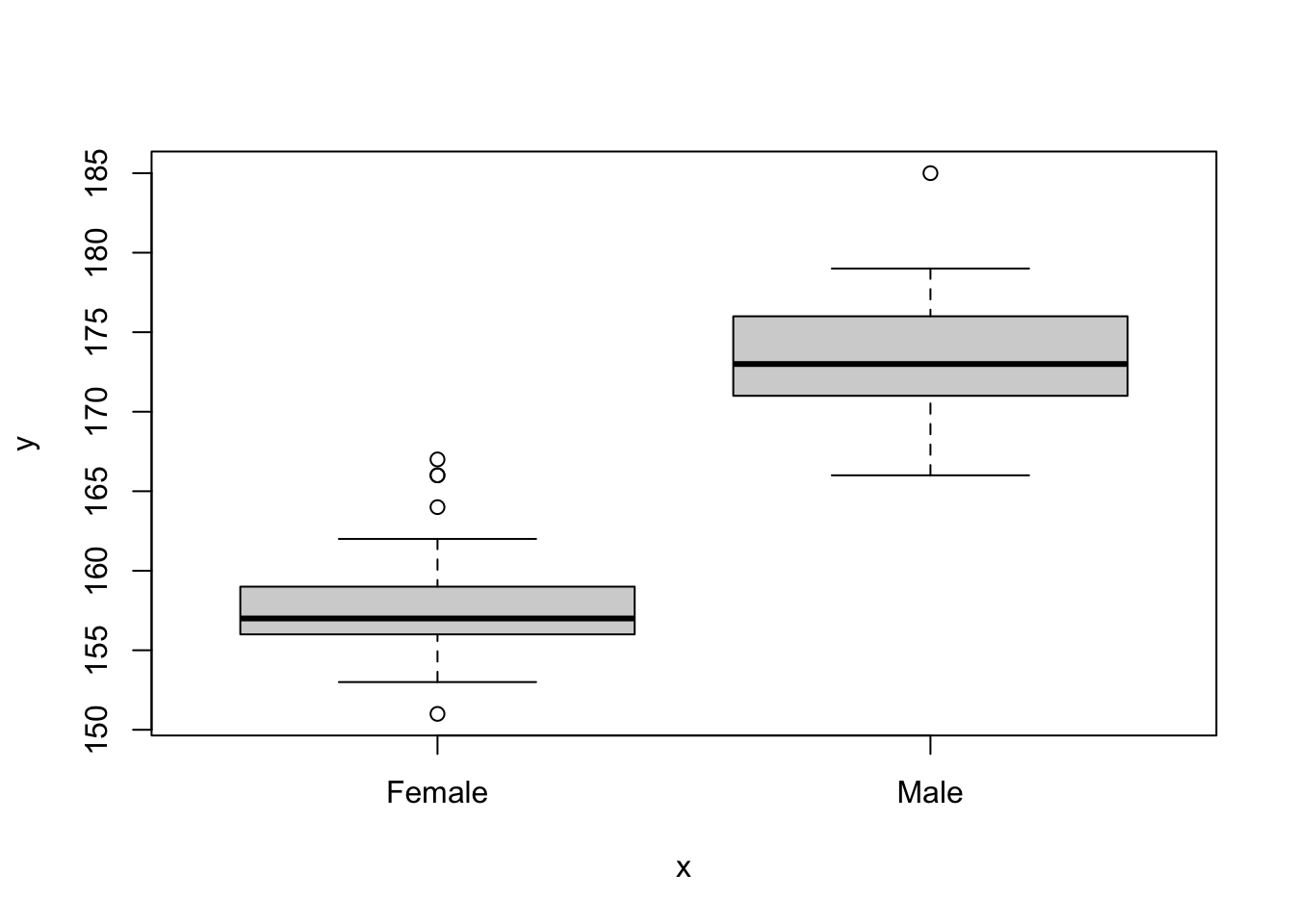
This data manipulation is useful surprisingly often.
9.3 Exercise: Temperature effects on egg laying dates
Data have been collected on great tits (musvit) at SDU for several years. Your task today is to analyse these data to answer the question: is egg laying date associated with spring temperature? The idea here is that warmer springs will lead to earlier egg laying which could have negative consequences to the population if their caterpillar food source doesn’t keep pace with the change.
You are provided with two data sets: one on the birds and another on weather. You will need to process these using tools in the dplyr package, and combine them (using left_join) for analysis.
The first data set, eggDates.csv, is data from the SDU birds project. The data are arranged in columns where each column is a year and each row is a nest. The data in each column is the day of the year that the first egg in the nest was laid.
These data do NOT fulfil the “tidy data” standard where each variable gets a column. In this case,a single variable (first egg date) gets many columns (one for each year), and column headers are data (the years). The data will need to be processed before you can analyse it.
You will need to use pivot_longer to fix this issue so that you produce a version of the data with three columns - nestNumber, Year and dayNumber.
The second dataset, AarslevTemperature.csv, is a weather dataset from Årslev near Odense. This dataset includes daily temperatures records for several years. You will need to summarise this data to obtain a small dataset that has the weather of interest - average temperature in the months of February to April for each year.
To answer the question, you will need to join these data sets together.
Import the data and take a look at it with
headorstr.Use
pivot_longerto reformat the data. This might take a bit of trial and error - don’t give up!
Maybe this will help: The first argument in the pivot_longer command (cols) tells R which columns contain the data you are interested in (in this case, these are y2013,y2014 etc). Then the names_to argument tells R what you want to name the new column from this data (in this case, Year). Then, the values_to argument tells R what the data column should be called (e.g. Day). In addition, there is a useful argument called names_prefix that will remove the part of the column name (e.g. the y of y2013)
You should also make sure that the Year column is recognised as being a numeric variable rather than a character string. You can do this by adding a command using mutate and as.numeric, like this mutate(Year = as.numeric(Year))
You should end up with a dataset with three columns as described above.
Calculate the mean egg date per year using
summarise(remember togroup_bythe year first). Take a look at the data.Import the weather data and take a look at it with
headorstr.Use
filtersubset to the months of interest (February-April) and thensummarisethe data to calculate the mean temperature in this period (remember togroup_byyear). Look at the data. You should end up with a dataset with two columns -yearandmeanSpringTemp.Join the two datasets together using
left_join. You should now have a dataset with columnsnestNumber,Year,dayNumberandmeanSpringTempplot a graph of
meanSpringTempon the x-axis anddayNumberon the y-axis.
Now you should be able to answer the question we started with: is laying date associated with spring temperatures.