Chapter 18 ANCOVA: Linear models with categorical and continuous explanatory variables
In the previous chapter we looked at linear models where there is a continuous response variable and two categorical explanatory variables (we call this type of linear model two-way ANOVA). In this chapter we will look at linear models where the explanatory variables are both continuous and categorical. You can think of these as a cross between ANOVA and linear regression. These types of models are often called “ANCOVA” or Analysis of Covariance.
In a simple case, you might be interested in a model with a continuous response variable (e.g. height) and a continuous and a categorical explanatory variable (e.g. hand length and sex). The categorical variable may have any number of levels, but the simplest case is two (e.g. sex with male and female levels).
Some of these possible outcomes are illustrated in Figure 18.1. We might see that neither of the two explanatory variables has a significant effect. We might see that one does but not the other. We might see an interaction effect (where the effect of one variable, e.g. hand length, depends on the other, e.g. sex). We might also see an interaction effect but no main effect.
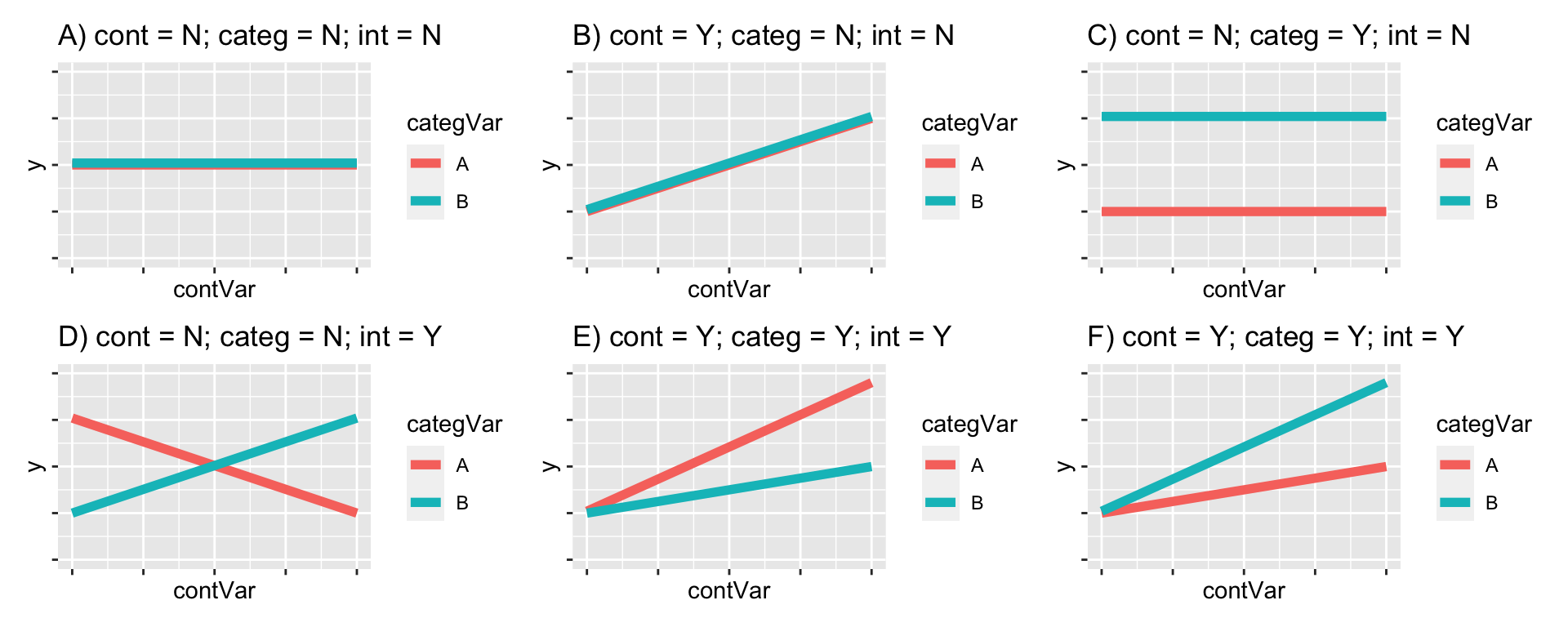
Figure 18.1: Some potential results of the experiment. There may be a significant effect (or not) of both of the main effects (diet and genotype) and there may be a significant interaction effect (or not).
18.1 The height ~ hand length example.
In a previous class (linear regression) you explored the relationship between hand length and height. The aim there was (1) to determine if the relationship (i.e. the slope) was significantly different from 0, and (2) to estimate the equation of the relationship so you could make predictions of height from hand length.
Here we will extend that example by asking whether there are differences between males and females. We’ll use the same morphometry.csv dataset of body measurements.
Remember to load the dplyr, magrittr and
ggplot packages, and to set your working directory
correctly.
We’ll begin by plotting the data (Figure 18.2).
morph <- read.csv("CourseData/morphometry.csv") %>%
mutate(Height = Height / 10, HandLength = HandLength / 10) # mm -> cm
(A <- ggplot(morph, aes(
x = HandLength, y = Height,
colour = Sex
)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE))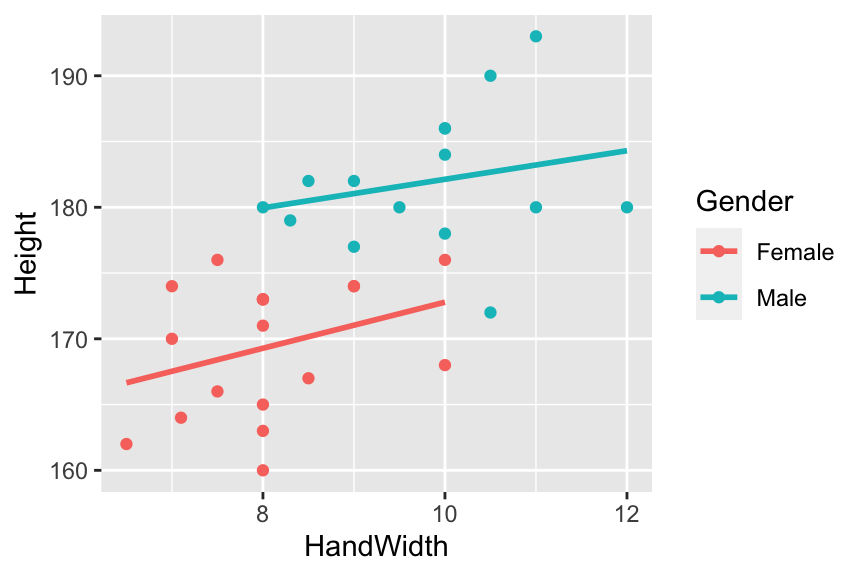
Figure 18.2: ANCOVA on hand length vs. height data in males and females
This shows the results of the ANCOVA model before we have even fit it! You can see that our two continuous variables, Height (the response variable) and HandLength (one of the explanatory variables) are associated: there is an overall positive relationship between HandLength and Height. You can also see that Sex (the categorical explanatory variable) is important: for any given hand length, the male line sits above the female one, so males tend to be taller. For example, at a hand length of 20cm a female is ~164cm tall while a male would be about ~171cm tall. The two slopes look fairly similar. These observations leave us with the following questions: (1) are the intercepts (the height difference between the sexes) significantly different? (2) are the slopes for males and females significantly different (or would a model with a single common slope, but different intercepts, be better)?
Now we can fit our model using the lm function. The model formula is Height ~ HandLength + Sex + HandLength:Sex. The HandLength and Sex are the so called main effects while HandLength:Sex represents the interaction between them (i.e. it is used to address the question “does the effect of hand length differ between the sexes?”). R knows that is fitting an ANCOVA type model rather than a two-way ANOVA because it knows the type of variables that it is dealing with. You can see this if you ask R to tell you what the class of the variables are:
## [1] "character"## [1] "numeric"The first step should, as before, be to check out the diagnostic plots:
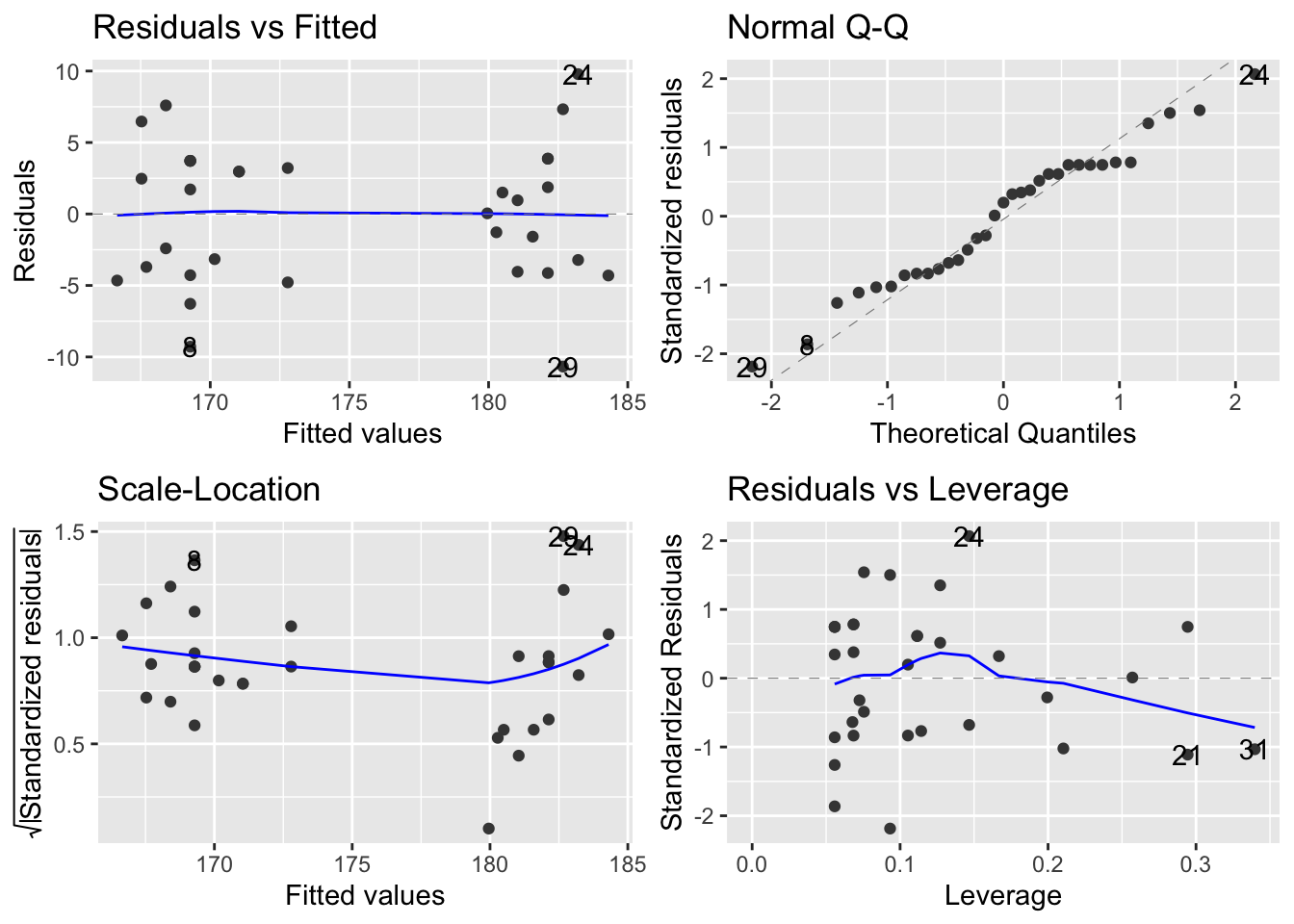
These look good. No evidence of non-normality in the residuals, no heteroscedasticity and no weird outliers.
18.2 Summarising with anova
Now we can get the anova table of our ANCOVA model (yes, I know that sounds strange).
## Analysis of Variance Table
##
## Response: Height
## Df Sum Sq Mean Sq F value Pr(>F)
## HandLength 1 10358.5 10358.5 677.1554 < 2.2e-16 ***
## Sex 1 876.6 876.6 57.3069 3.431e-12 ***
## HandLength:Sex 1 37.4 37.4 2.4417 0.1202
## Residuals 151 2309.9 15.3
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1This type of sequential sum of squares Analysis of Variance table should be getting fairly familiar to you now, but let’s unpack what this means. There are four rows in the summary table - one for each of the terms in the model (HandLength, Sex and HandLength:Sex), and one for the Residuals (the unexplained variation that remains after fitting the model). The table includes degrees of freedom (Df), sum of squares (Sum Sq), mean sum of squares (Mean Sq) and the associated F and p-values (F value and Pr(>F).
You can interpret the mean sum of squares column in terms of the amount of variation in the response variable (Height) that is explained by the term: The table first tells us the amount of variation (in terms of Mean Sum of Squares) in Height that is captured by hand length (1.035846^{4}). Then it tells us that an additional bit of variation 876.62 is captured if we allow the intercepts to vary with sex. Then it tells us that a small additional amount of variation is explained by allowing the slope to vary between the sexes (the interaction) 37.35. Finally, there is a bit of unexplained variation left over (Residuals) 15.3. So you can see that hand length explains most variation, followed by sex, followed by the interaction between them.
You would report from this table something like this:
Hand length and sex both explain a significant amount of the variation in height (ANCOVA - HandLength: F = 677.155, d.f. = 1 and 151, p<0.001; Sex: F = 57.307, d.f. = 1 and 151, p<0.001). The interaction effect was not significant, which means that the slopes of the relationship between hand length and height are not significantly different between the sexes (ANCOVA - F = 2.442, d.f. = 1 and 151, p = 0.12).
It is of course useful to take the interpretation a bit further. You could do this with reference to the plot - e.g. Figure X shows the clear positive relationship between hand length and height, and shows that males tend to be taller than females at any given hand length.
Because the interaction term is not significant, the two slopes are statistically indistinguishable. Good practice is therefore to simplify the model by dropping the interaction, leaving a model with a single common slope but different intercepts for the two sexes (a “parallel lines” model). We refit like this:
It is this simpler model that we now interpret.
18.3 The summary of coefficients (summary)
To put some quantitative numbers on this description of the pattern we need to get the summary of the simplified (parallel lines) model from R.
##
## Call:
## lm(formula = Height ~ HandLength + Sex, data = morph)
##
## Residuals:
## Min 1Q Median 3Q Max
## -21.0129 -2.2501 0.1381 2.3274 19.1092
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 78.7438 6.5133 12.090 < 2e-16 ***
## HandLength 4.2840 0.3427 12.500 < 2e-16 ***
## SexMale 6.8720 0.9121 7.534 4.09e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.93 on 152 degrees of freedom
## Multiple R-squared: 0.8272, Adjusted R-squared: 0.8249
## F-statistic: 363.8 on 2 and 152 DF, p-value: < 2.2e-16This summary table gives the coefficients of the statistical model, their standard errors, and the t-test results of whether the estimate is different from 0. This is the same as the summary tables given for ANOVA and linear regression.
In the ANOVA summary tables, the estimates were given in relation to the reference level – the (Intercept) – and these ANCOVA summary tables are no different. Interpreting is best done with reference to the graph of the data and fitted model outputs (the graph above).
The reference level (the (Intercept)) is the intercept for the line for the first level of the categorical variable (Females, in this case). Here the model estimates that the intercept for Females is at 78.74 (i.e. if you extended the line out to the left it would eventually cross the y-axis at this point). The next coefficient HandLength is the slope of the relationship (4.28) – because we dropped the interaction, this common slope applies to both sexes. Then we have SexMale: this coefficient (6.87) is the difference in intercept between the Female and Male lines – i.e. at any given hand length, males are estimated to be about 6.9cm taller than females.
We can therefore do some simple arithmetic to get the equations (i.e. slopes and intercepts) of the lines for both sexes. Both lines share the same slope (4.28). For females the intercept is 78.74 (the reference level, read directly from the table). For males the intercept is 78.74 + 6.87 = 85.62.
We could add these equations to our reporting of the results.
Figure X shows the clear positive relationship between hand length and height, and shows that males are taller than females at a given hand length. The two fitted lines are parallel: both have a slope of 4.28cm of height per cm of hand length, and the male line is offset upwards by 6.9cm.
You could check these by using geom_abline to add the two (parallel) lines to the plot (just as a “sanity check”).
A +
geom_abline(intercept = coef(mod_B)[1], slope = coef(mod_B)[2]) + # female
geom_abline(
intercept = coef(mod_B)[1] + coef(mod_B)[3],
slope = coef(mod_B)[2]
) # maleAt the bottom of the summary output we are given the \(R^2\) values. Because this model has more than one term (i.e. variable) in it we should use the adjusted \(R^2\) value. This has been corrected for the fact that the model has extra explanatory variables. So in this case, we could report that the model explains 82.5% of variation in Height (Adjusted \(R^2\) = 0.82) - not bad!
So, to describe this summary table more generally - the coefficients can be slopes, intercepts, differences between slopes, and differences between intercepts. They are slopes and intercepts for the first level of the categorical variable, and for the subsequent levels they are differences. Piecing these together can be hard to figure out without reference to the plot of the data and model fits - another good reason to plot your data!