Chapter 17 Linear regression: models with a single continuous explanatory variable
Linear regression models, at their simplest, estimate linear (straight-line) relationships between two continuous variables. As an example, picture the relationship between height and hand length (Figure 17.1). In this figure there is a clear relationship between the two variables, and the straight line running through the cloud of data points is the fitted linear regression model.
The aim of linear regression is to (1) determine whether there is a meaningful statistical relationship between the explanatory variable(s) and the response variable, and (2) quantify those relationships by estimating their characteristics. These characteristics include the slope and intercept of fitted models, and the amount of variation explained by variables in the model.
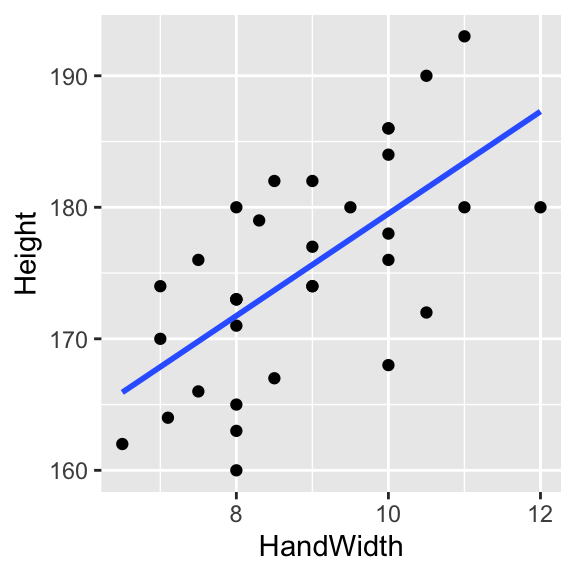
Figure 17.1: A linear regression model fitted through data points.
17.1 Some theory
To understand linear regression models it is important to know that the equation of a straight line is \(y = ax + b\). In this equation, \(y\) is the response variable and \(x\) is the explanatory variable, and \(a\) and \(b\) are the slope and intercept of the line with the vertical axis (y-axis). These (\(a\) and \(b\)) are called coefficients. These are illustrated in Figure 17.2.
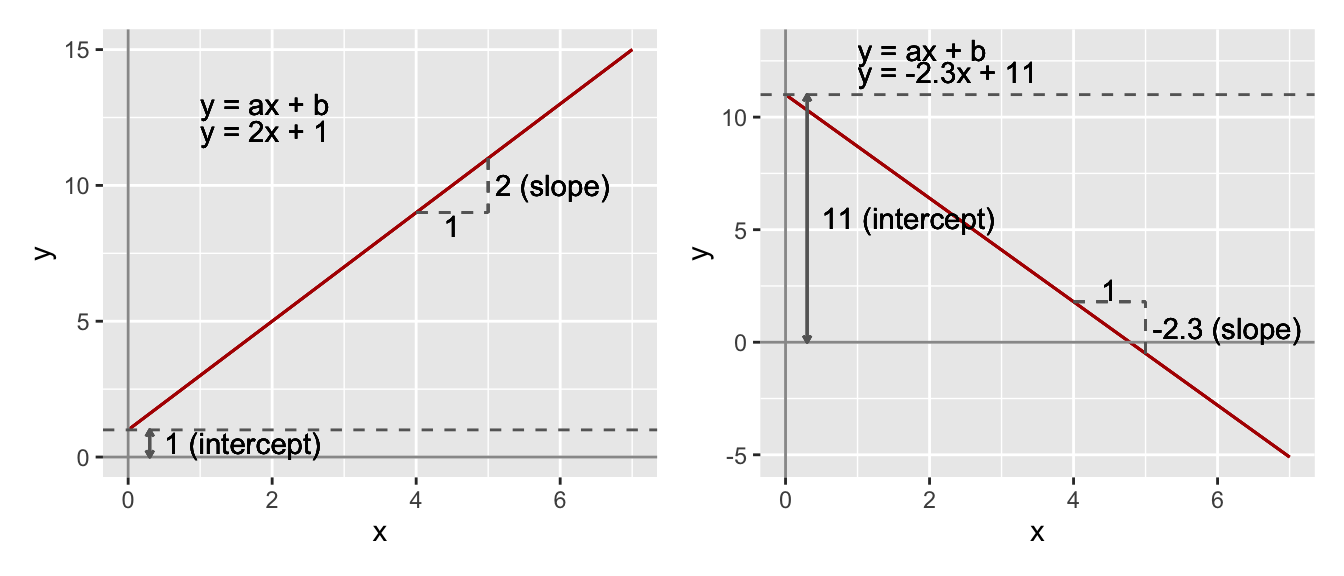
Figure 17.2: The equation of straight lines.
When looking at data points on a graph, unless all of the points are arranged perfectly along a straight line, there will be some distance between the points and the line. These distances, measured parallel to the vertical axis, are called residuals (you have encountered them before in this course). These residuals represent the variation left after fitting the line (a linear model) through the data. Because we want to fit a model that explains as much variation as possible, it is intuitive that we should wish to minimise this residual variation.
One way of doing this is by minimising the sum of squares of the residuals (again, you have come across this concept a few times before). In other words, we add up the squares of each of the residuals. We square the values rather than simply adding up the residuals themselves because we want to ensure that the positive and negative values don’t cancel each other out (a square of a negative number is positive). This method is called least squares regression and is illustrated in Figure 17.3: Which is the best fitting line?
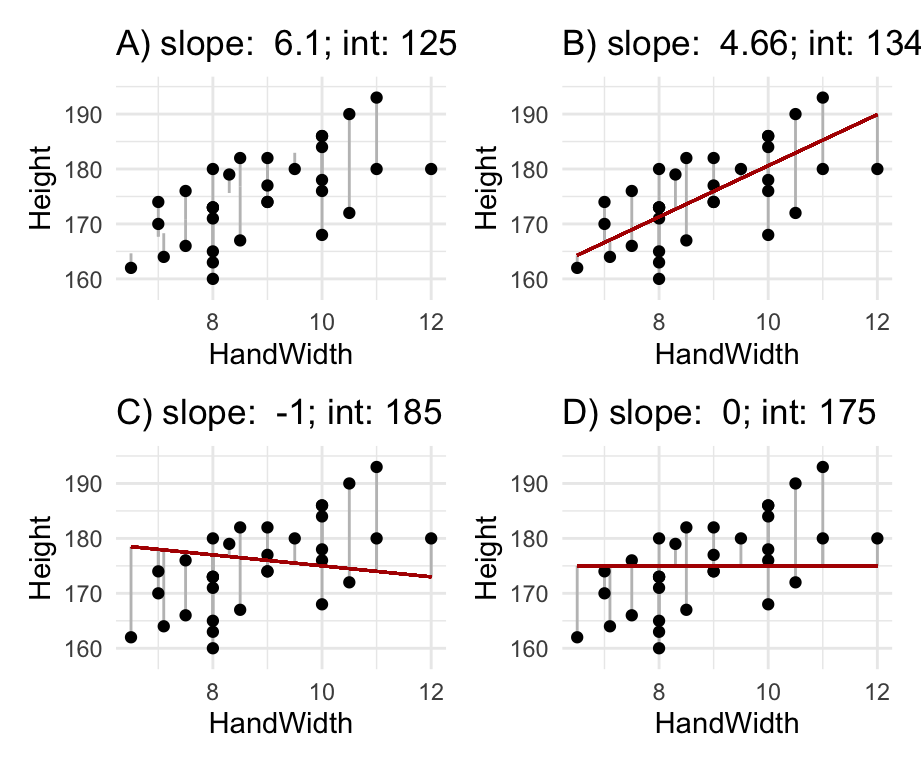
Figure 17.3: Residuals and least squares: which is the best fitting line?
In fact, these residuals represent “error” caused by factors including measurement error, random variation, variation caused by unmeasured factors etc. This error term is given the label, \(\epsilon\). Thus we can write the model equation as:
\[y = ax+b+\epsilon\]
Sometimes, this equation is written with using the beta symbol (\(\beta\)) for the coefficients, so that the intercept is \(\beta_0\) and the slope is \(\beta_1\) for example.
\[y = \beta_0 + \beta_1 x+\epsilon\]
The idea is that this equation, and its coefficients and error estimates, describe the relationship we are interested in (including the error or uncertainty).
Together this information allows us to not only determine if there is a statistically significant relationship, but also what the nature of the relationship is, and the uncertainty in our estimates.
17.2 Evaluating a hypothesis with a linear regression model
Usually, the most important hypothesis test involved with a linear regression model relates to the slope: is the slope coefficient significantly different from 0?, or should we fail to reject the null hypothesis that the slope is no different from 0.
Sometimes hypotheses like this are a bit boring, because we already know the answer before collecting and analysing the data. What we usually don’t know is the nature of the relationship (the slope, intercept, their errors, and amount of variation explained). Usually it is more interesting and meaningful to focus on those details.
The following example, where we focus on the relationship between hand length and height, is one of these “boring” cases: we already know there is a relationship. Nevertheless, we’ll use this example because it helps us understand how this hypothesis test works.
The aim of this section is to give you some intuition on how the hypothesis test works.
We can address the slope hypothesis by calculating an F-value in a similar way to how we used them in ANOVA. Recall that F-values are ratios of variances. To understand how these work in the context of a linear regression we need to think clearly about the slope hypothesis: The null hypothesis is that the slope is not significantly different to 0 (that the data can be explained by random variation). The alternative hypothesis is that the slope is significantly different from 0.
The first step in evaluating these hypotheses is to calculate what the total sum of squares8 is when the null hypothesis is true (Figure 17.4A) - this value is the total variation that the model is trying to explain.
Then we fit our model using least squares and figure out what the residual sum of squares is from this model (Figure 17.4B). This is the amount of variation left after the model has explained some of the total variation - it is sometimes called residual error, or simply error.
The difference between these two values is the explained sum of squares, which measures the amount of variation in \(y\) explained by variation in \(x\). The rationale for this is that the model is trying to explain total variation. After fitting the model there will always be some unexplained variation (“residual error”) left. If we can estimate total variation and unexplained variation, then the amount of variation explained can be calculated with a simple subtraction:
\[Total = Explained + Residual\] … and, therefore … \[Explained = Total - Residual\]
Before using these values we need to standardise them to control for sample size. This is necessary because sum of squares will always increase with sample size. We make this correction by dividing our sum of squares measures by the degrees of freedom. The d.f. for the explained sum of squares is 1, and the d.f. for the residual sum of squares is the number of observations minus 2. The result of these calculations is the mean explained sum of squares (mESS) and the mean residual sum of squares (mRSS). These “mean” quantities are variances, and the ratio between them gives us the F-value. Notice that this is very similar to the variance ratio used in the ANOVA.
\[F = \frac{mESS}{mRSS}\]
If the explained variance (mESS) is large compared to the residual error variance (mRSS), then F will be large. The size of F tells us how likely or unlikely it is that the null hypothesis is true. When F is large, the probability that the slope is significantly different from 0 is high. To obtain the actual probabilities, the F-value must be compared to a theoretical distribution which depends on the two degrees of freedom (explained and residual d.f.). Once upon a time you would have looked this up in a printed table, but now R makes this very straightforward.
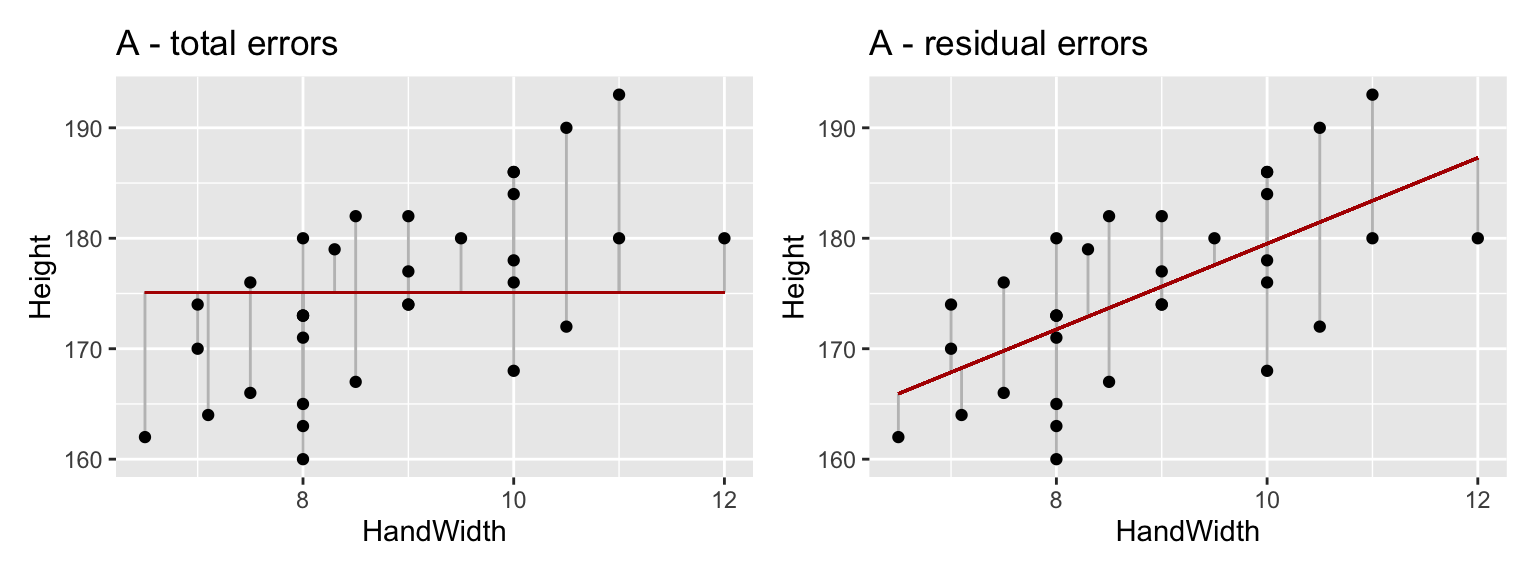
Figure 17.4: (A) the total variation around the overall mean Height value (B) the residual error of the model.
17.3 Assumptions
These models have similar assumptions to the other linear models9. These are (1) that the relationship between the variables is linear (hence the name); (2) that the data are continuous variables; (3) that the observations are randomly sampled; (4) that the errors in the model (the “residuals”) can be described by a normal distribution; and (5) and that the errors are “homoscedastic” (that they are constant through the range of the data). You can evaluate these things by looking at diagnostic plots after you have fitted the model. See page 112-113 in GSWR for a nice explanation.
17.4 Worked example: height-hand length relationship
Let’s now use R to fit a linear regression model to estimate the relationship between hand length and height. One application for such a model could be to predict height from a hand print, for example left at a crime scene. The data are body measurements (in cm) from a sample of people.
Remember to load the dplyr, magrittr and
ggplot packages, and to set your working directory
correctly.
First, load the data:
morph <- read.csv("CourseData/morphometry.csv") %>%
mutate(Height = Height / 10, HandLength = HandLength / 10)We should then plot the data to make sure it looks OK.
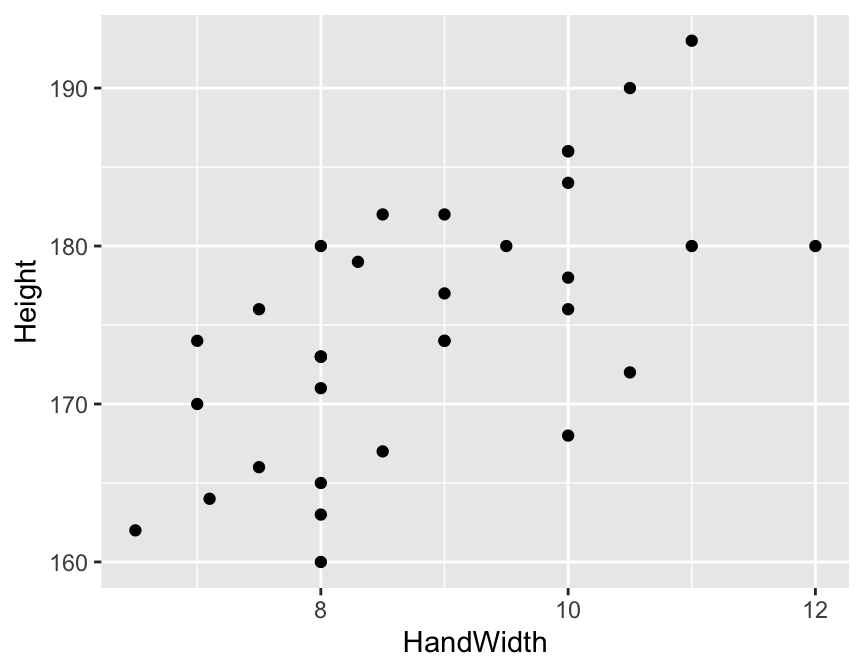
This looks OK, and the relationship looks fairly linear. Now we can fit a model using the lm function (same as for ANOVA!).10
The response variable is always the one we would like to predict, in this case Height. The explanatory variable (sometimes called the predictor) is HandLength. These are added to the model using a formula where they are separated with the ~ (“tilde”) symbol: Height ~ HandLength. In the model expression, we also need to tell R where the data are using the data = argument. We can save the model as an R object by naming it e.g. mod_A <-.
Before proceeding further we should evaluate the model using a diagnostic plot. We can do this using the autoplot function in the ggfortify package (you may need to install and/or load the package).
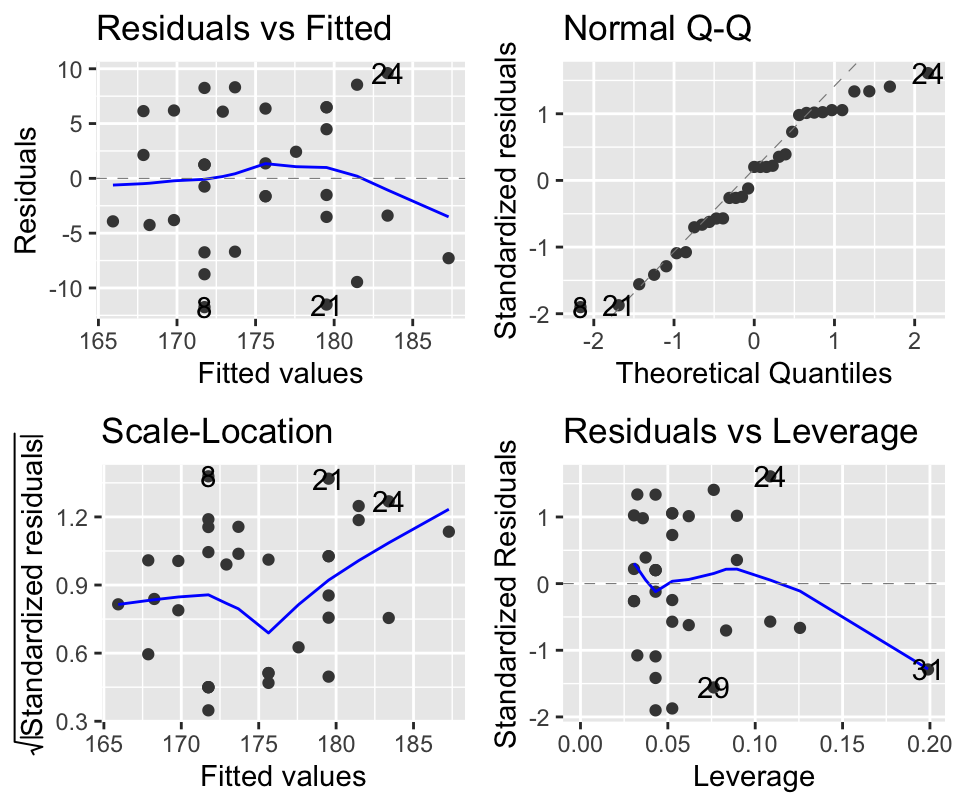 These diagnostic plots allow you to check that the assumptions of the model are not violated. On the left are two plots which (more or less) show the same thing. They show how the residuals (the errors in the model) vary with the predicted value (height). Looking at the plots allows a visual test for constant variance (homoscedasticity) along the range of the data. In an ideal case, there should be no pattern (e.g. humps) in these points. On the top right is the QQ-plot which shows how well the residuals match up to a theoretical normal distribution. In an ideal case, these points should line up on the diagonal line running across the plot. The bottom right plot shows “leverage” which is a measure of how much influence individual data points have on the model. Outliers will have large leverage and can mess up your model. Ideally, the points here should be in a cloud, with no points standing out from the others. Please read the pages 112-113 in the textbook GSWR for more on these. In this case, the model looks pretty good.
These diagnostic plots allow you to check that the assumptions of the model are not violated. On the left are two plots which (more or less) show the same thing. They show how the residuals (the errors in the model) vary with the predicted value (height). Looking at the plots allows a visual test for constant variance (homoscedasticity) along the range of the data. In an ideal case, there should be no pattern (e.g. humps) in these points. On the top right is the QQ-plot which shows how well the residuals match up to a theoretical normal distribution. In an ideal case, these points should line up on the diagonal line running across the plot. The bottom right plot shows “leverage” which is a measure of how much influence individual data points have on the model. Outliers will have large leverage and can mess up your model. Ideally, the points here should be in a cloud, with no points standing out from the others. Please read the pages 112-113 in the textbook GSWR for more on these. In this case, the model looks pretty good.
Now that we are satisfied that the model doesn’t violate the assumptions we can dig into the model to see what it is telling us.
To test the (slightly boring) slope hypothesis we use the anova function (again, this is the same as with the ANOVA).
## Analysis of Variance Table
##
## Response: Height
## Df Sum Sq Mean Sq F value Pr(>F)
## HandLength 1 10358.5 10358.5 491.6 < 2.2e-16 ***
## Residuals 153 3223.8 21.1
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1When you run this function, you get a summary table that looks exactly like the one you got with an ANOVA. There are degrees of freedom (Df), Sums of Squares (Sum Sq), Mean Sums of Squares (Mean Sq) and the F value and p-value (Pr(>F)).
The most important parts of this table are the F value (491.604) and the p-value (0.000): as described above, large F values lead to small p-values. This tells us that it is unlikely that the null hypothesis is true and we should accept the alternative hypothesis (that height is associated with hand length).
We could report the results of this hypothesis test like this: There was a statistically significant association between hand length and height (F = 491.6036, d.f. = 1,153, p < 0.001)
Now we can dig deeper by asking for a summary of the model.
##
## Call:
## lm(formula = Height ~ HandLength, data = morph)
##
## Residuals:
## Min 1Q Median 3Q Max
## -28.5880 -2.1640 -0.3922 2.4068 27.8185
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 45.1269 5.5429 8.141 1.27e-13 ***
## HandLength 6.1469 0.2772 22.172 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.59 on 153 degrees of freedom
## Multiple R-squared: 0.7626, Adjusted R-squared: 0.7611
## F-statistic: 491.6 on 1 and 153 DF, p-value: < 2.2e-16This summary has a lot of information. First we see Call which reminds us what the formula we have used to fit the model. Then there is some summary information about the residuals. Ideally these should be fairly balanced around 0 (i.e. the Min value should be negative but with the same magnitude as Max). If they are wildly different, then you might want to check the data or model. In this case they look OK.
Then we get to the important part of the table - the Coefficients. This lists the coefficients of the model and shows first the Intercept and then the slope, which is given by the name of the explanatory variable (HandLength here). For each coefficient we get the Estimate of its value, and the uncertainty in that estimate (the standard error (`Std. Error)).
These estimates and errors are each followed by a t value and a p-value (Pr(>|t|)). These values provide a test of whether the slope/intercept is different from zero. In this case they both are. The t-tests are indeed doing t-tests of these estimates, in the same way that a regular t-test works, so that the significance depends on the ratio between signal (the estimate) and the noise (the standard error). This is illustrated for the coefficient estimates for our model in Figure 17.5.
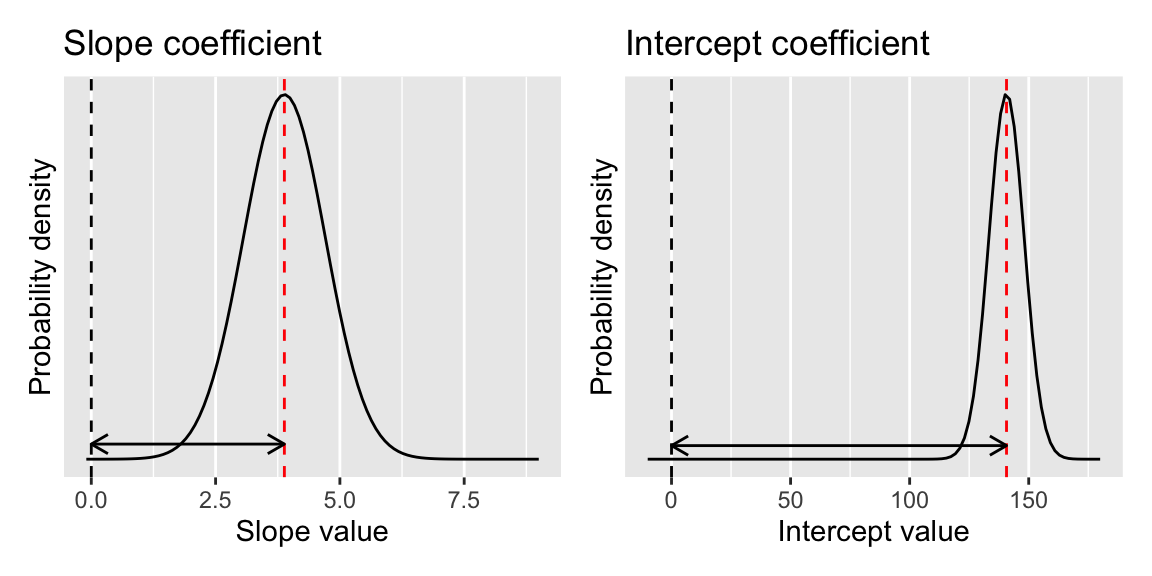
Figure 17.5: Illustration of the coefficient estimates for our model. The peak of the distribution is at the coefficient estimate, and the spread of the distribution indicates the standard error of the mean for the estimate. The statistical significance of the coefficient is determined by the degree of overlap with 0.
The summary then gives some information about the amount of residual variation left after the model has been fitted (this is the \(\epsilon\) term in the equations at the start of this chapter). Then we are told what the \(R^2\) value is 0.7626. The adjusted \(R^2\) is for use in multiple regression models, where there are many explanatory variables, and should not be used for this simple regression model. Multiple regression is not really a separate technique: it is the same lm you are using here, just with more explanatory variables added using + (you will meet it in the ANCOVA and model-evaluation chapters). The main extra thing to watch for is multicollinearity — strongly correlated explanatory variables — which is discussed in the chapter on linear model assumptions. So what does \(R^2\) actually mean?
\(R^2\) is the square of the correlation coefficient \(r\) and is a measure of the amount of variation in the response variable (Height) that is explained by the model. If all the points were sitting on the regression line, the \(R^2\) value would be 1. This idea is illustrated in Figure 17.6.
We could describe the model like this:
There is a statistically significant association between hand length and height (F = 491.6036, d.f. = 1,153, p < 0.001) The equation of the fitted model is: Height = 6.15(\(\pm\) 0.28) \(\times\) HandLength + 45.13(\(\pm\) 5.54). The model explains 76% of the variation in height (\(R^2\) = 0.763).
… or maybe, The model, which explained 76% of the variation in height, showed that the slope of the relationship between hand length and height is 6.15 \(\pm\) 0.28 which is significantly greater than 0 (t = 22.17, p < 0.01)
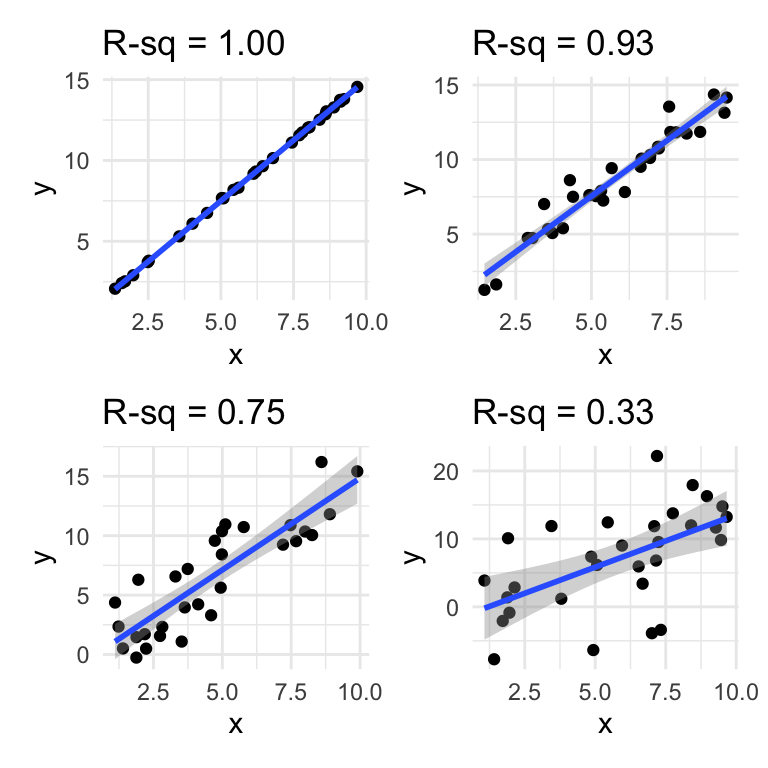
Figure 17.6: An illustration of different R-squared values.
A plot is usually a good idea because it is easier for the reader to interpret than an equation, or coefficients. The ggplot2 package has a neat and simple function called geom_smooth which will add the fitted regression line to simple models like this. For linear regression models you simply need to tell it to use method = "lm". This will plot the fitted regression model, and will add, by default, a shaded “ribbon” which represents the so called “95% confidence interval” for the fitted values. These are approximately 2 times the standard error.
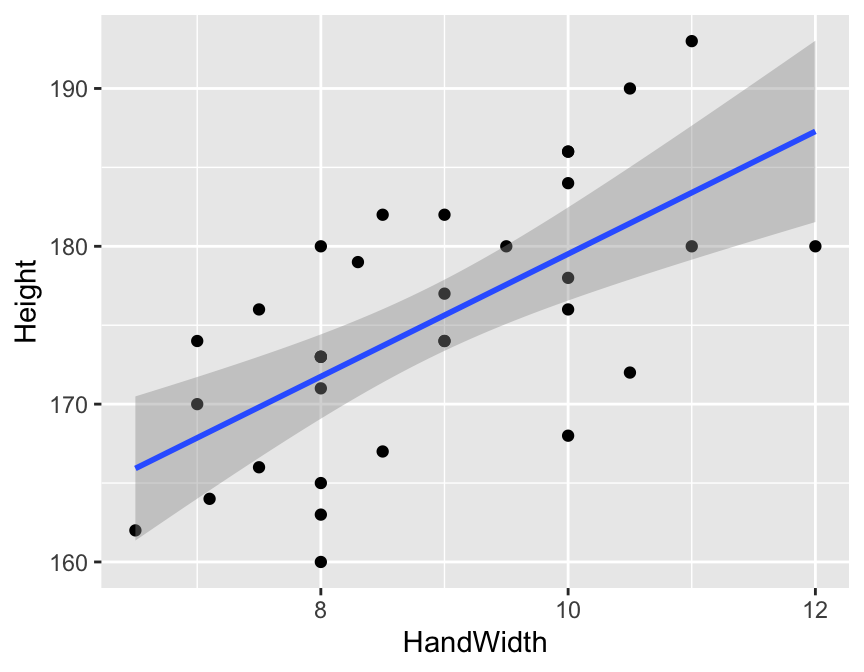
Question: If police find a hand print at a crime scene with a hand length of 20cm, what is your best guess of the height of the person involved?
17.5 Exercise: Chirping crickets
Male crickets produce a “chirping” sound by rubbing the edges of their wings together: the male cricket rubs a sharp ridge on his wing against a series ridges on the other wing. In a 1948 study on striped ground cricket (Allonemobius fasciatus), the biologist George W. Pierce recorded the frequency of chirps (vibrations per second) in different temperature conditions.
Crickets are ectotherms so their physiology and metabolism is influenced by temperature. We therefore believe that temperature might have an effect on their chirp frequency.
The data file chirps.csv contains data from Pierce’s experiments. Your task is to analyse the data and find (1) whether there is a statistically significant relationship between temperature and chirp frequency and (2) what that relationship is.
The data has two columns - chirps (the frequency in Hertz) and temperature (the temperature in Fahrenheit). You should express the relationship in Celsius.
Import the data
Use
mutateto convert Fahrenheit to Celsius (Google it)Plot the data
Fit a linear regression model with
lmLook at diagnostic plots to evaluate the model
Use
anovato figure out if the effect of temperature is statistically significant.Use
summaryto obtain information about the coefficients and \(R^2\)-value.Summarise the model in words.
Add model fit line to the plot.
Can I use cricket chirp frequency as a kind of thermometer?