Chapter 5 An R refresher
Learning goals
By the end of this chapter you should be able to:
- Use RStudio to run code from scripts.
- Create and inspect basic objects in R.
- Work with vectors and data frames.
- Import a CSV file using tidyverse tools.
- Make simple plots and summaries.
Prerequisites
- You have R and RStudio installed.
A tiny motivating example
Let’s make a tiny plot so we know everything is working.
library(tidyverse)
mydata <- data.frame(
body_length_cm = c(4.2, 5.1, 5.6, 6.8, 7.4),
body_mass_g = c(9.5, 12.1, 14.0, 18.2, 21.5)
)
ggplot(mydata, aes(x = body_length_cm, y = body_mass_g)) +
geom_point()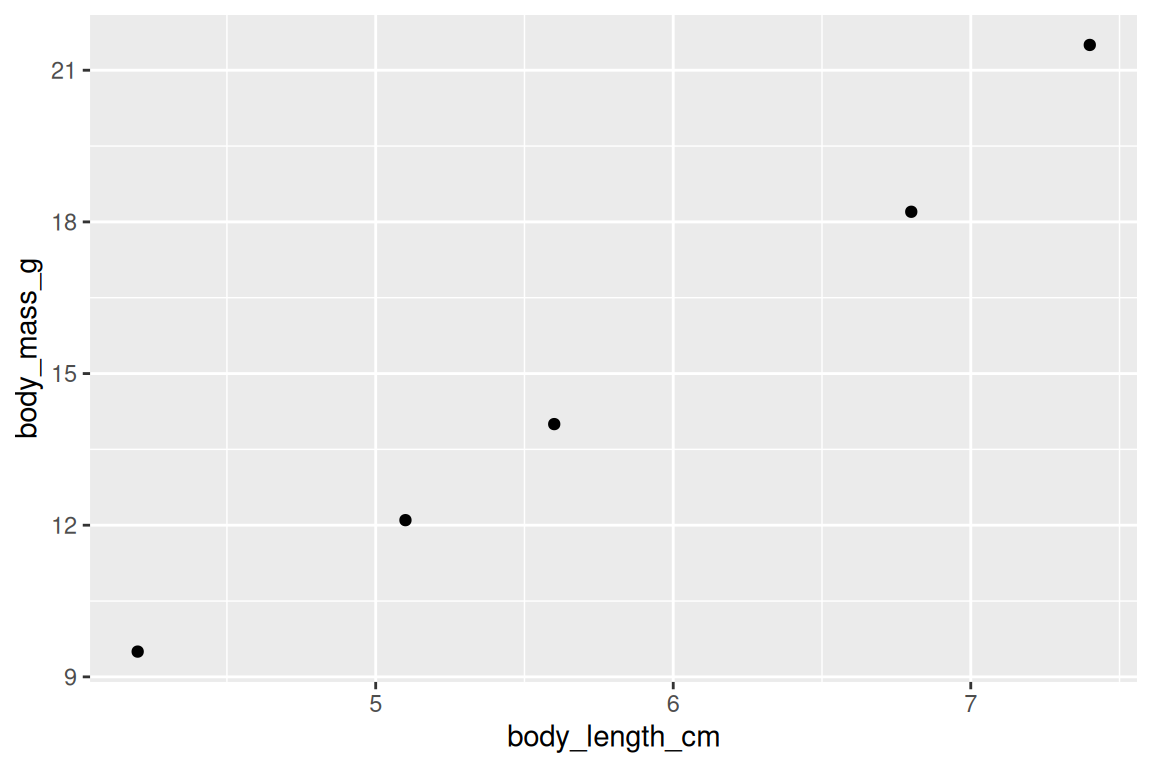
What just happened: Each point is an individual. This matters because almost every plot in this course follows the same pattern: data + aesthetics + geom.
Try this: Change one value and re-run. What changes on the plot?
5.1 Getting started with RStudio
What we’re about to do: We will set up a simple workflow so your work is reproducible.
RStudio is not R itself. It is the interface where you write scripts, run code, and view results.
Do this: Open RStudio and create a new script
(File > New File > R Script). Save it as
practice.R.
Why this matters: Scripts let you save, revisit, and debug your work. Copy-pasting into the console will not scale.
Common mistake: Running everything in the console and losing your work. If this happens, start a script and re-run your commands there.
Takeaway: Work in scripts, not just the console.
5.2 Getting help
What we’re about to do: Learn how to ask R for help.
What just happened: ? opens a help page when you know a function name; ?? searches when you do not.
Try this: Look up mean or plot and read the arguments section.
Takeaway: R has built-in help for almost everything.
5.3 R as a calculator
What we’re about to do: Use R for basic arithmetic and logic.
## [1] 7## [1] -3## [1] 2## [1] 21## [1] 15.6## [1] 30.74085## [1] 243## [1] 23.4## [1] 2.35## [1] 0.1823216## [1] 2.718282## [1] 0.7781513Logical comparisons:
## [1] TRUE## [1] FALSE## [1] TRUE## [1] TRUE## [1] TRUE## [1] FALSETakeaway: R handles arithmetic and logical tests directly.
5.4 Objects and vectors
What we’re about to do: Create objects and simple vectors.
## [1] 4Vectors are simple sequences of values.
A <- 1:5
B <- c(1, 3, 6, 1, 7, 9)
C <- seq(1, 12, 2)
D <- seq(1, 5, 0.1)
E <- rep(c("Male", "Female"), each = 3)
G <- rep(c("Male", "Female"), c(2, 4))
Try changing seq() or rep() arguments. What
changes?
Common mistake: Forgetting c() when creating a list of values.
Takeaway: Vectors are the building blocks of most data in R.
5.5 Manipulating vectors
What we’re about to do: Do arithmetic on vectors.
## [1] 1 3 6 1 7 9## [1] 3 9 18 3 21 27## [1] -1 1 4 -1 5 7## [1] 1 2 3 4 5 1 3 6 1 7 9## [1] 1 6 18 4 35 54## [1] 1.0000000 0.6666667 0.5000000 4.0000000 0.7142857 0.1111111What just happened: R works element-by-element when vector lengths match.
Takeaway: Vectorised operations are fast and convenient.
5.6 Missing values, infinity, and NaN
What we’re about to do: See how R handles missing values and edge cases.
## [1] NA## [1] 4.5## [1] Inf## [1] -Inf## [1] NaN## [1] NaNTakeaway: Use na.rm = TRUE when you want to ignore missing values.
5.7 Data frames
What we’re about to do: Create and inspect a data frame.
height <- c(173, 145, 187, 155, 179, 133)
sex <- c("Male", "Female", "Male", "Female", "Male", "Female")
age <- c(17, 22, 32, 20, 27, 30)
mydata <- data.frame(height = height, age = age, sex = sex)
mydata## height age sex
## 1 173 17 Male
## 2 145 22 Female
## 3 187 32 Male
## 4 155 20 Female
## 5 179 27 Male
## 6 133 30 FemaleInspect a data frame:
## height age sex
## Min. :133.0 Min. :17.00 Length :6
## 1st Qu.:147.5 1st Qu.:20.50 N.unique :2
## Median :164.0 Median :24.50 N.blank :0
## Mean :162.0 Mean :24.67 Min.nchar:4
## 3rd Qu.:177.5 3rd Qu.:29.25 Max.nchar:6
## Max. :187.0 Max. :32.00## 'data.frame': 6 obs. of 3 variables:
## $ height: num 173 145 187 155 179 133
## $ age : num 17 22 32 20 27 30
## $ sex : chr "Male" "Female" "Male" "Female" ...Subset rows/columns:
## height age sex
## 1 173 17 Male## [1] 17 22 32 20 27 30## [1] 17## height age sex
## 2 145 22 Female
## 4 155 20 Female
## 6 133 30 FemaleTakeaway: Data frames are tables: rows are observations, columns are variables.
5.8 Classes and factors
What we’re about to do: Check classes and use factors for categories.
## [1] "numeric"## [1] "character"## [1] "data.frame"Some functions need categorical data to be factors:
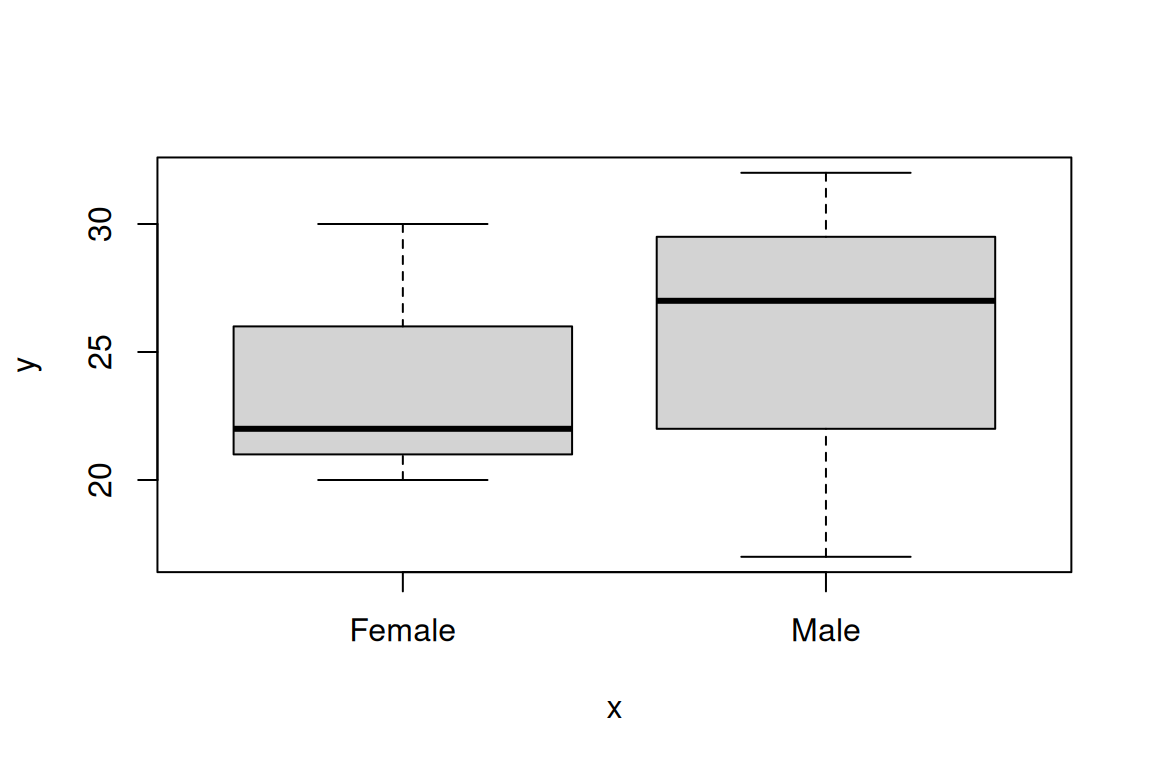
## 'data.frame': 6 obs. of 3 variables:
## $ height: num 173 145 187 155 179 133
## $ age : num 17 22 32 20 27 30
## $ sex : Factor w/ 2 levels "Female","Male": 2 1 2 1 2 1Common mistake: Forgetting to convert characters to factors for categorical plots.
Takeaway: Use factors for categorical variables when needed.
5.9 Organising your work and importing data
What we’re about to do: Import a CSV file, and meet the two functions you will see for doing this.
Keep your data in a CourseData folder inside your project. We will use relative paths throughout this course. If you do not have CourseData, download it from the course site.
There are two common ways to read a CSV file into R, and you will come across both:
read.csv()comes with base R. It returns adata.frameand, withstringsAsFactors = TRUE, turns text columns into factors — which is convenient for the statistics later in the course.read_csv()comes from thereadrpackage (part of the tidyverse). It is a little faster, prints a short summary of the column types it guessed, and returns a tibble (a modern data frame). It leaves text columns as character.
Both work well and you will see both in other people’s code. To keep things consistent, this book uses read.csv() from here on.
What just happened: read.csv() imported the data as a data.frame and, thanks to stringsAsFactors = TRUE, stored the text columns as factors.
Try this: Run str(carni) and compare it to summary(carni).
Common mistake: File not found. Check spelling and folder names.
Takeaway: This book uses read.csv(); read_csv() is the tidyverse alternative you will also encounter.
5.10 Inspecting the data
## Order SuperFamily Family Genus
## Carnivora:112 Caniformia:57 Viverridae :32 Mustela : 9
## Feliformia:55 Mustelidae :30 Herpetes: 8
## Felidae :19 Panthera: 5
## Canidae :18 Canis : 4
## Hyaenidae : 4 Martes : 4
## Procyonidae: 4 Felis : 3
## (Other) : 5 (Other) :79
## Species FW SW
## Acinonyx jubatus : 1 Min. : 0.050 Min. : 0.050
## Ailuropoda melanoleuca : 1 1st Qu.: 1.245 1st Qu.: 1.400
## Alopex lagopus : 1 Median : 3.400 Median : 3.895
## Aonyx capensis : 1 Mean : 18.099 Mean : 20.084
## Arctictis binturong : 1 3rd Qu.: 10.363 3rd Qu.: 11.592
## Arctogalidia trivirgata: 1 Max. :320.000 Max. :365.000
## (Other) :106
## FB SB LS GL
## Min. : 1.00 Min. : 1.00 Min. :1.000 Min. : 23.50
## 1st Qu.: 15.25 1st Qu.: 15.68 1st Qu.:2.500 1st Qu.: 53.80
## Median : 33.00 Median : 33.75 Median :3.000 Median : 63.00
## Mean : 53.40 Mean : 56.43 Mean :3.232 Mean : 65.79
## 3rd Qu.: 57.38 3rd Qu.: 57.17 3rd Qu.:3.800 3rd Qu.: 73.50
## Max. :365.00 Max. :459.50 Max. :8.800 Max. :168.00
## NAs :2 NAs :21
## BW WA AI LY AM
## Min. : 0.01 Min. : 21.0 Min. : 56.0 Min. : 96 :57
## 1st Qu.: 41.88 1st Qu.: 54.5 1st Qu.: 183.8 1st Qu.:141 365 : 8
## Median : 116.25 Median : 70.0 Median : 365.0 Median :162 730 : 5
## Mean : 249.31 Mean :104.0 Mean : 407.8 Mean :182 913 : 4
## 3rd Qu.: 286.88 3rd Qu.:117.0 3rd Qu.: 592.5 3rd Qu.:207 450 : 2
## Max. :1650.00 Max. :730.0 Max. :1080.0 Max. :408 1095 : 1
## NAs :50 NAs :49 NAs :82 NAs :63 (Other):35
## IB
## :55
## 12 :27
## 6 :13
## 24 : 2
## 27 : 2
## 4 : 2
## (Other):11## [1] 112 17## [1] "Order" "SuperFamily" "Family" "Genus" "Species"
## [6] "FW" "SW" "FB" "SB" "LS"
## [11] "GL" "BW" "WA" "AI" "LY"
## [16] "AM" "IB"The dataset includes life history variables. For example:
FW= Female body weight (kg)GL= Gestation length (days)BW= Birth weight (g)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.050 1.245 3.400 18.099 10.363 320.0005.11 Tables and summary statistics
## [1] "factor"## [1] "Ailuridae" "Canidae" "Felidae" "Hyaenidae" "Mustelidae"
## [6] "Procyonidae" "Ursidae" "Viverridae"##
## Ailuridae Canidae Felidae Hyaenidae Mustelidae Procyonidae
## 1 18 19 4 30 4
## Ursidae Viverridae
## 4 32## Ailuridae Canidae Felidae Hyaenidae Mustelidae Procyonidae
## 120.000000 9.050000 31.432105 33.540000 3.989000 3.642500
## Ursidae Viverridae
## 198.250000 2.672813Takeaway: Tables and summaries give you a quick sense of patterns before you plot.
5.12 Basic plotting
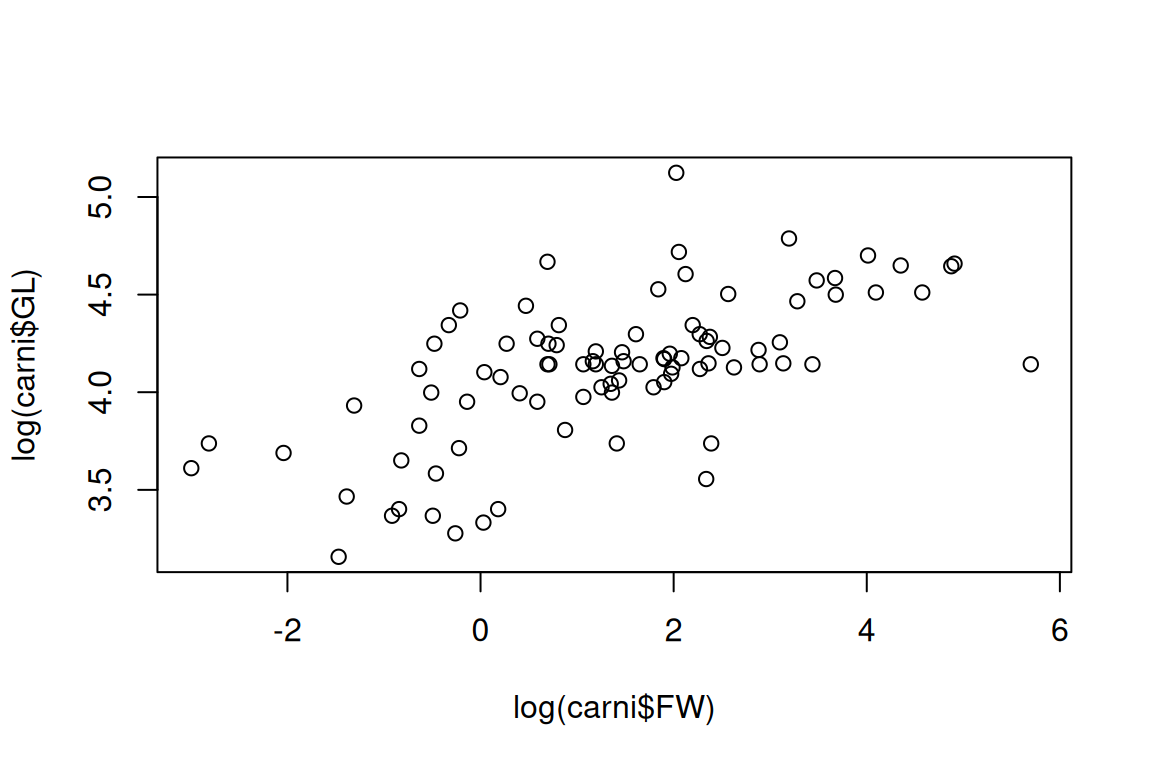
Figure 5.1: A simple scatter plot
Interpretation: Species with larger female body mass tend to have longer gestation lengths.
- What to look for:
- Is the relationship roughly linear?
- Are there any clear outliers?
Try this: Remove the log and compare the shape.
5.13 R packages
Packages extend base R. Install once, then load each session.
Add your library(…) calls at the top of scripts so
your code runs every time.
5.14 Exercise: Californian bird diversity
Surveys on bird abundances were carried out near Oakland, California.2 The locations were of different ages, which lets us ask how species richness changes through time.
5.14.1 The data
The file is suburbanBirds.csv. Columns: Name, Year, HabitatIndex, nIndividuals, nSpecies.
5.14.2 Your tasks
Level 1 (warm-up)
Import the data and check the columns with
str(). Checkpoint: You should see the five columns listed above.Calculate the mean, minimum, and maximum of
nSpecies. Checkpoint: You should get three numbers.
Level 2 (practice)
Create a new column
Age = 1975 - Yearand check it looks sensible. Checkpoint: Younger suburbs have smallerAgevalues.Plot
AgevsnSpecieswithplot(). Checkpoint: The x-axis is age and the y-axis is species richness.
Level 3 (extension)
- Re-plot with a smoother (e.g.
lines(lowess(Age, nSpecies))). Does it change your interpretation?
Hint: If your plot is empty, check your column names with names().
5.15 Key takeaways
- Use scripts for reproducible work.
- Vectors and data frames are the core data types.
read.csv()imports CSV files;read_csv()is the tidyverse alternative.- Check classes with
str()and convert tofactor()when needed. - Always inspect your data before analysing it.
Vale, T. R., & Vale, G. R. (1976). Suburban bird populations in west-central California. Journal of Biogeography, 157–165.↩︎